Configuration Hierarchy
Checkly provides a three-tier configuration system that allows for flexible alert management across your organization:Account Level
Account Level
- Applied to all checks unless overridden
- Organization-wide defaults
- Simplifies management at scale
- Consistent baseline behavior
Group Level
Group Level
- Override account defaults for checks within Groups
- Team-based alert preferences
- Service-specific requirements
- Departmental escalation policies
Check Level
Check Level
- Fine-tune specific check behavior
- Handle special requirements
- Debug and testing scenarios
- Legacy system accommodations
Configuration Inheritance
Understanding how settings cascade through the hierarchy:- Check-level settings always take highest precedence
- Group-level settings override account defaults for member checks
- Account-level settings provide the baseline for all other configurations
- Explicit overrides can be enabled/disabled at group level
Runs you cancel never trigger alerts. No failure, degraded, or recovery notification is sent for a cancelled run, regardless of the settings above.
Alert Configuration
Account-Level
Configure organization-wide defaults that apply to all checks: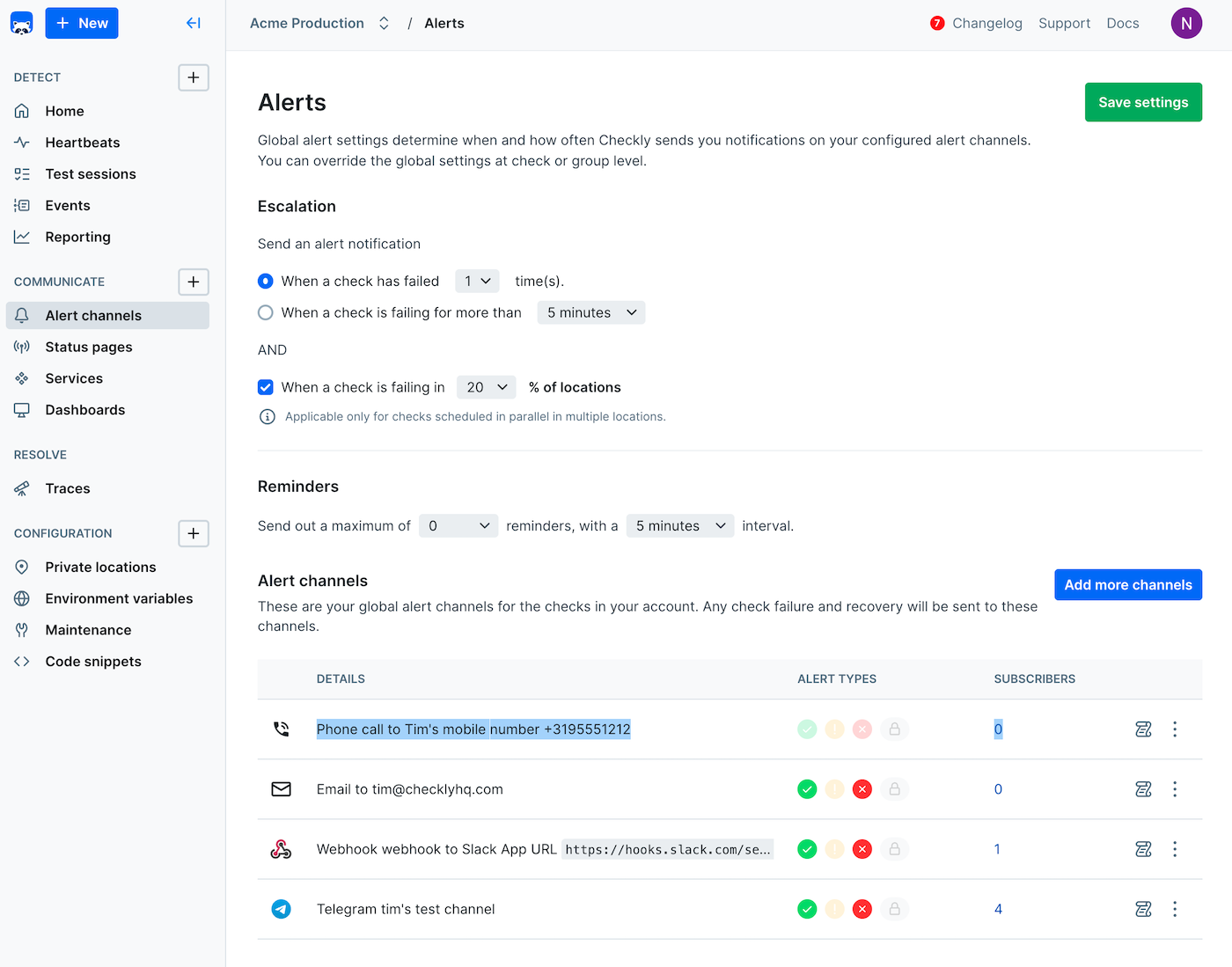
- Consistency: Uniform alerting behavior across all monitoring
- Efficiency: Configure once, apply everywhere
- Compliance: Meet organizational alerting requirements
- Scalability: Easy to manage large numbers of checks
Group-Level
Configure alerts for teams and service categories: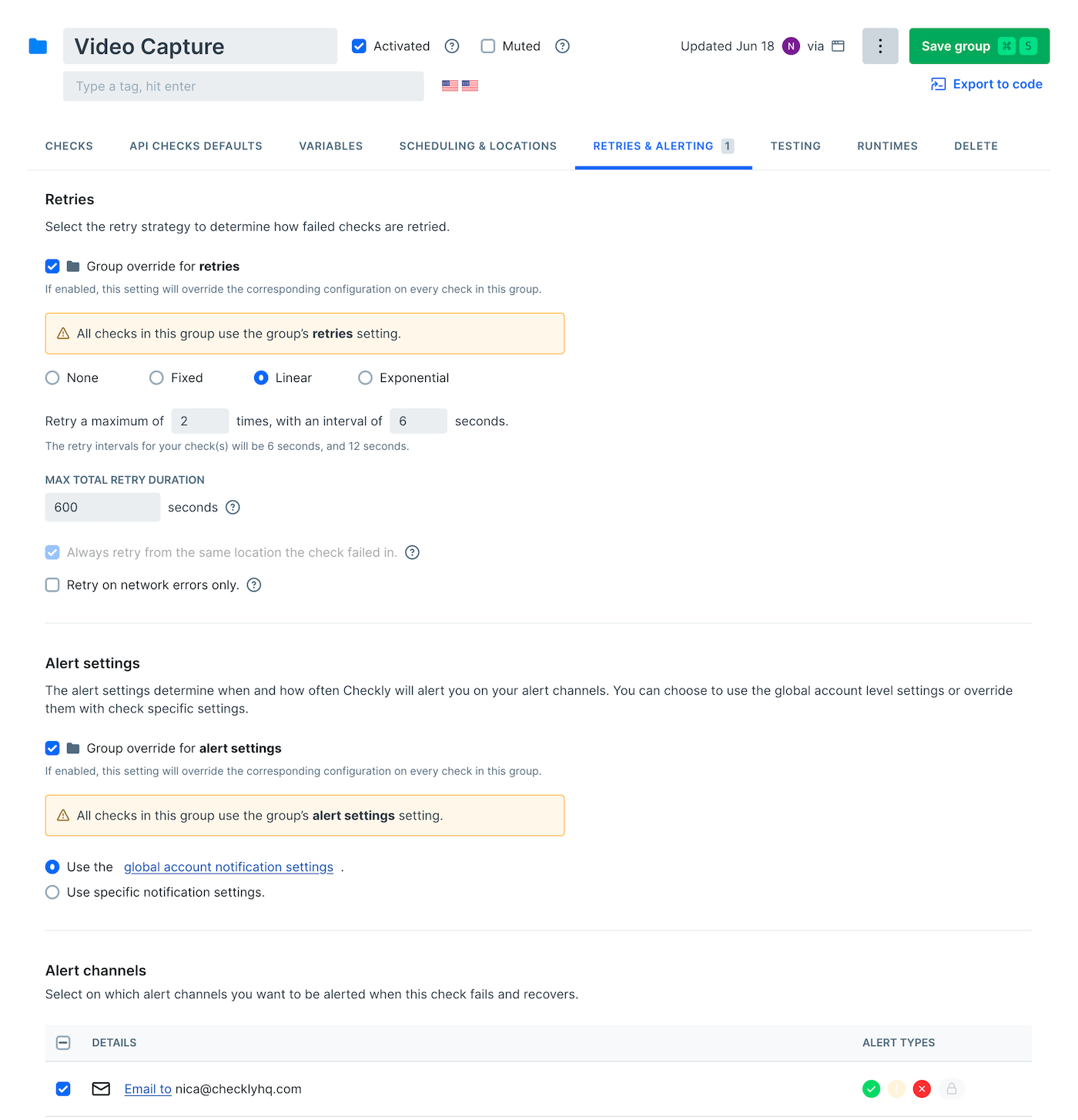
Group Override
Configure how group settings interact with individual checks:If checked, Group settings override individual check settings- Group settings take precedence
- Ensures consistency within teams
- Prevents individual check drift
- Simplifies management
- Check-level customization allowed
- Handle special cases easily
- Legacy system accommodation
- Granular control when needed
Check-Level
Fine-tune alerting for specific checks with unique requirements: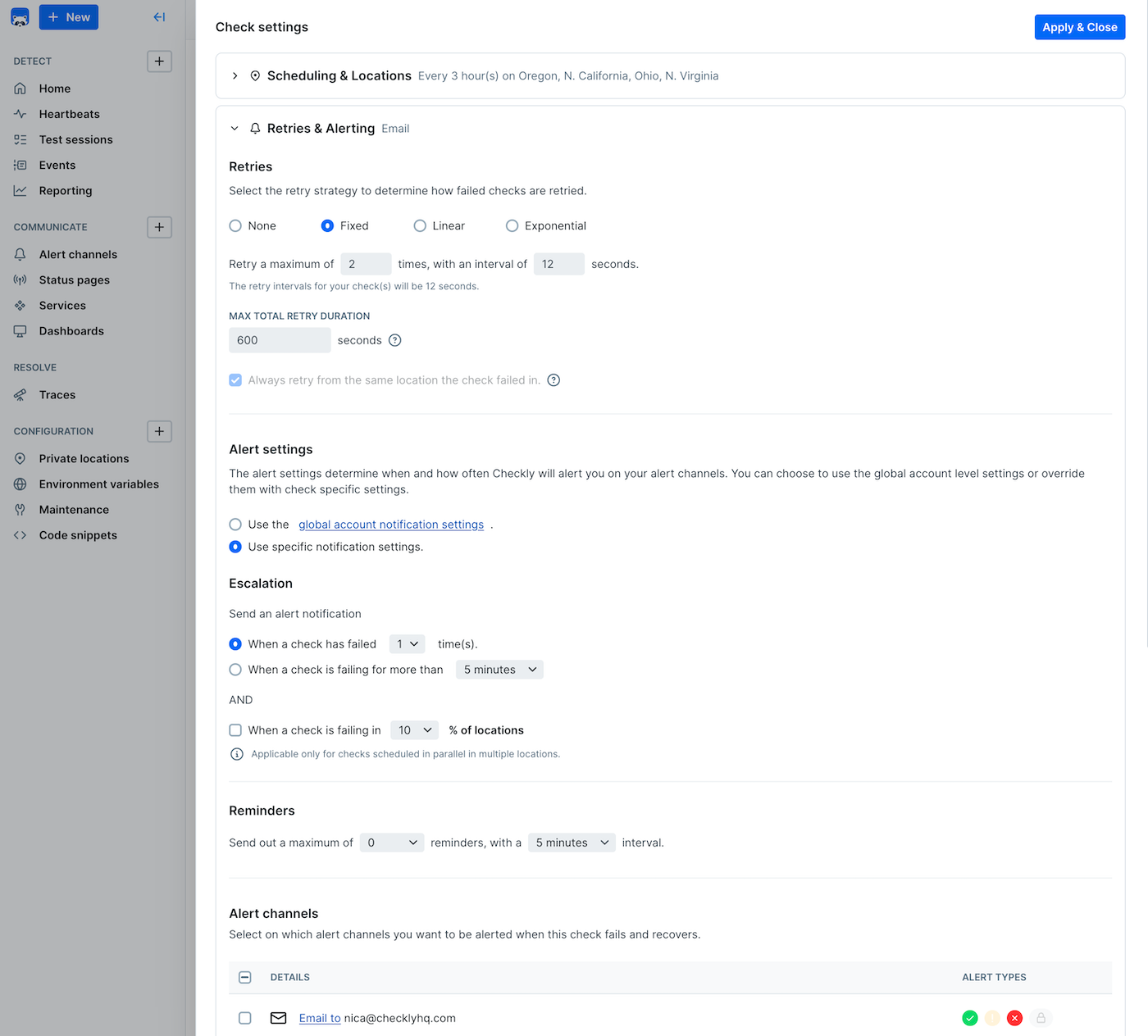
Start with conservative alert settings and gradually tune based on your team’s response patterns and service reliability characteristics. Too many alerts can be worse than too few.
Escalation Configuration
The escalation box allows you to decide when an alert should be triggered. We give you three options that are applied to all checks: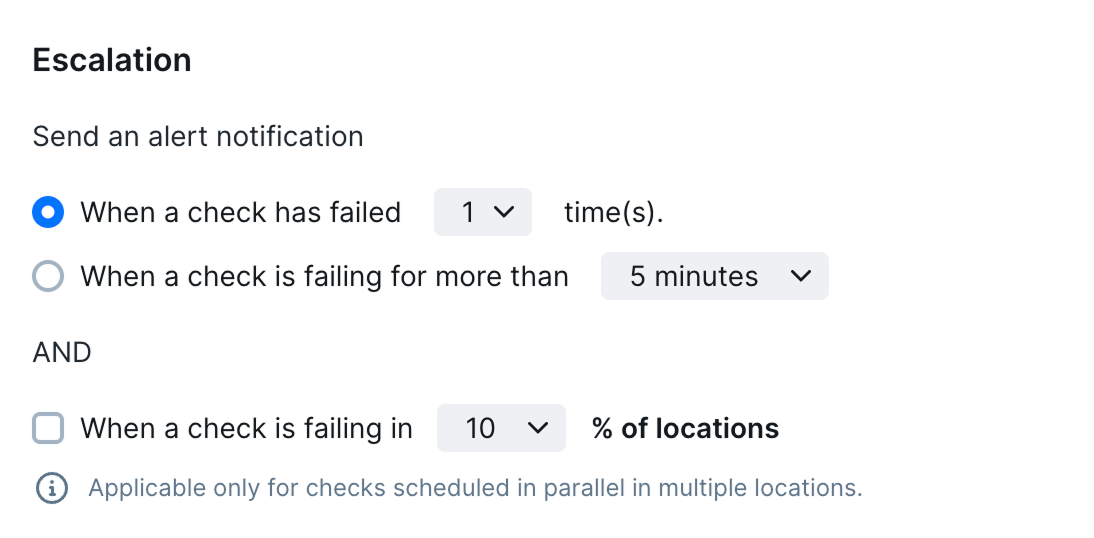
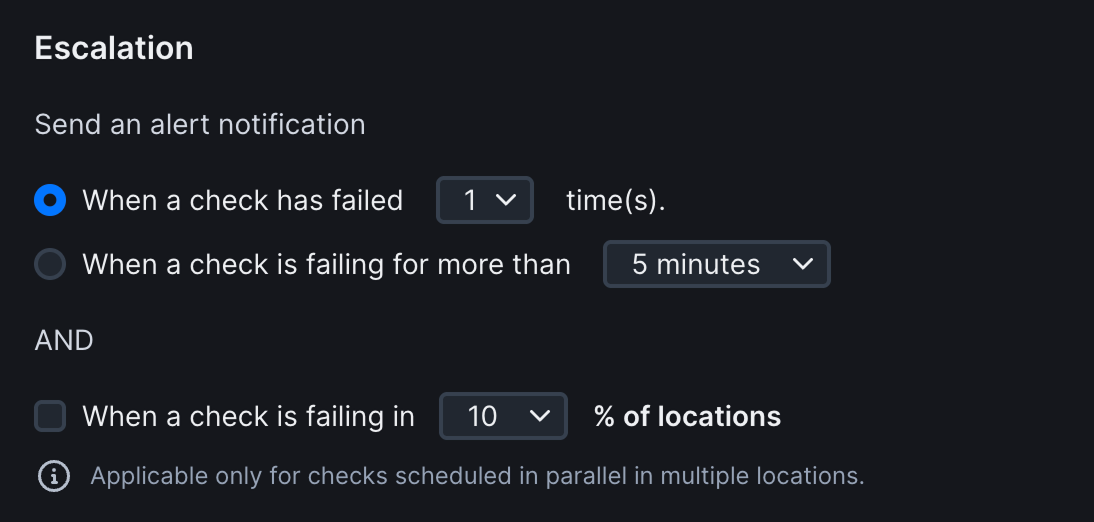
Run-Based Escalation
Get alerted when a check has failed a number of times consecutively. We call this a Run Based escalation. Note that failed checks retried from a different region are not considered “consecutive”.

- Consecutive Failure Counting
- Counts failed check runs in sequence
- Resets counter on successful run
- Cross-location failures count as one run
- Retries don’t count as separate runs
- Predictable failure patterns
- Clear success/failure states
- Services with known reliability
- APIs with consistent behavior
Time-Based Escalation
We alert you when a check is still failing after a period of time, regardless of the amount of check runs that are failing. This option should mostly be used when checks are run very regularly, i.e. once every minute or five minutes.

- Monitors failure duration, not count
- Ideal for high-frequency checks
- Ignores individual run results
- Focuses on sustained problems
- Checks running every 1-5 minutes
- Services with intermittent issues
- Rate-limited APIs
- Network-dependent services
Location-Based Escalation
This option can be selected in addition to the run or time-based escalation settings and only affect checks running in parallel with two or more locations selected. When enabled, alerts will only be sent when the specified percentage of locations are failing. Use this setting to reduce alert noise and fatigue for services that can handle being unavailable from some locations before action is required.

- Reduces false positives from regional issues
- Focuses on global service problems
- Accommodates CDN and geo-distributed services
- Filters out single-location network problems
Reminder Configuration
Configure follow-up notifications for unresolved incidents.

When a check failure is resolved, we cancel any outstanding reminders so you don’t get mixed signals.
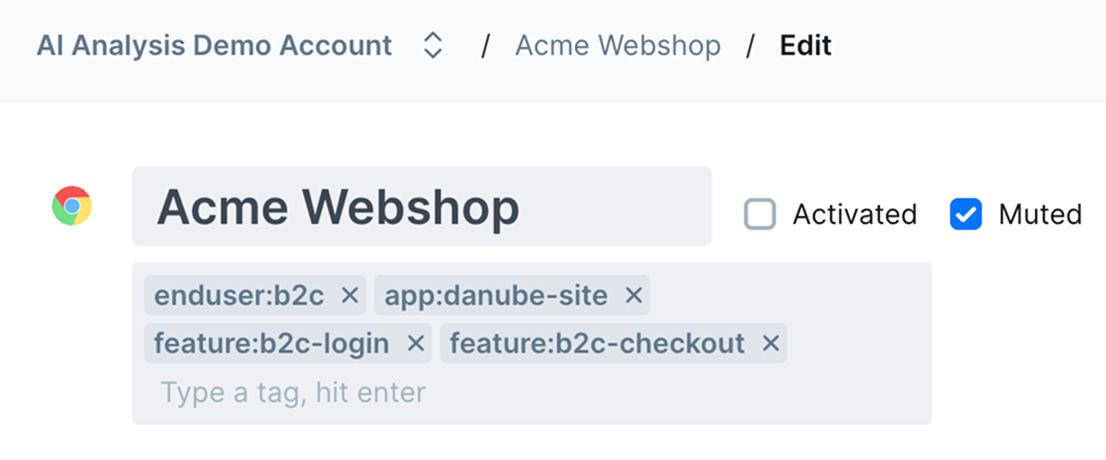
Muting and Temporary Controls
Toggling the “mute” checkbox on a check stops the sending of all alerts but keeps the check running. This is useful when your check might be flapping or showing other unpredictable behavior. Just mute the alerts but keep the check going while you troubleshoot.