

When adding a new feature to Checkly or refactoring some older piece, I tend to pick Heroku for rolling it out. But not always, because sometimes I pick AWS Lambda.
The short story:
- Developer Experience trumps everything.
- AWS Lambda is cheap. Up to a limit though. This impacts not only your wallet.
- If you need geographic spread, AWS is lonely at the top.
For the long story, read on.
The setup
Recently, I was doing a brainstorm at a startup here in Berlin on the future of their infrastructure. They were ready to move on from their initial, almost 100% Ec2 + Chef based setup.
Everything was on the table. But we crossed out a lot quite quickly:
- — way too much complexity
- — still too much complexity
- — Maybe, but no Docker support
- Elastic Beanstalk — Maybe, bit old but does the job
- Heroku
- Lambda
It became clear a mix of PaaS (Heroku, Beanstalk) and FaaS (Lambda, Zeit) was the way to go. What a surprise! That is exactly what I use for Checkly!
But when do you pick which model?
I chopped that question up into the following categories:
- Developer Experience / DX 🤓
- Ops Experience / OX 🐂 (?)
- Cost 💵
- Lock in 🔐
Note, these are list in order of importance. At least to me. YMMV and all that.
Onwards!
DX / Developer Experience 🤓
For Heroku, there is no developer experience when you start.
And I mean this in a good way.
You just build your app in your favorite IDE, with your favorite testing frameworks, debuggers, documentation generators, versioning etc. etc.
Heroku does not push itself onto your localhost.
I can't emphasize how important this is for my developer experience. And also for vendor lock in — see below.
Your development cycle is just so much quicker when you can run your whole stack on your local box. Without Docker preferably.
I can just set breakpoints in my code, inspect the API routes and controllers, update records in the database, tweak our Vue.js frontend, check the logs and iterate on that with near zero latency, restarts or anything: try doing that with your API gateway / Lambda setup.
In a nutshell:
- IDE & tooling integration
- Testing
- Debugging
- Packaging
All the above are a non-issue. Only when you git push does the PaaS platform need some hints from you. In the Checkly case a two line Procfile files that just points to what npm run command to kick of and how to run migrations.
release: cd api && node_modules/.bin/knex migrate:latest
web: npm start --prefix apiYou don't even need to use the heroku toolchain CLI, although its pretty nice.
✅ No proprietary services, shims, mocks, hoopla's and ding dongs necessary to design, build & test on your local machine.
✅ Come deploy time, a one/two liner in file.
✅ The above translates to easy & stable CI runs too.
For AWS Lambda, you can keep it simple too. Just fire up some sample from AWS and start hacking in the browser based IDE.
But no one really does that.
People tend to use the Serverless framework or something similar to deal with the vagaries of Lambda. And that's where the "fun" starts.
There is a whole cottage industry of plugins, mocks, libraries and services that try to bridge the gap between the Lambda/ FaaS / serverless runtime model and the local development experience.
Admittedly, Serverless (the framework) is not bad at this. You can use their serverless invoke local command to mock a local execution. You can use their suite of serverless-offline modules to mock out specific AWS dependencies like SQS or SNS.
This all works. Even better if you create a Docker container that has all the necessary dependencies to run this local Lambda environment for all your tests.
But notice this:
- We just added two pretty massive dependencies to our project: Serverless and Docker. Expect quirks and weird incompatibilities.
- You need to do all of this also on your CI platform to actually run the test. Your CI runs just went from 30 seconds to 3 minutes.
Probably the sanest advice I can give is to keep it simple and religiously abstract any business logic from any Lambda specific features. See vendor lock in below.
⚠️ The development experience is still messy. Serverless is on the right track, sort of.
❌ The "just write a function" mantra is not really true. You will need extra stuff.
OX / Ops Experience 🐂
So, this is now called "day two" or something. This is also where Lambda shines a bit more than in the DX category.
For Heroku the ops experience in general is pretty darn good. They deliver enough metrics and logging to get you out of many sticky situations. The CLI has a bunch of options to check database usage, restart / scale dynos etc.
Especially the database maintenance routine gets a shout out. Roll forward and roll back are also nice.
When you need more monitoring or logging you add 3rd party services from the addon marketplace. For our API we use the Grafana Cloud and AppOptics addons and they work as advertised.
But Heroku also has some stability issues. They had a massive outage recently — which luckily passed us by — and there are routing and dyno start issues. This is not a secret and generally well communicated using status emails.
Routing is still a total mystery to me, and no one really knows what "Dynos" actually are. Yes, the docs go into some detail but AWS just open sources their Firecracker containers powering Lambda.
✅ Gives you some easy to use tools to manage, optimize and troubleshoot for free.
✅ Third party integrations for monitoring and logging work great.
⚠️ Gets more mysterious and obscure the deeper you go. Some areas are totally off limits.
For AWS Lambda, It's a bit of a mixed bag. First the good points.
Stability and availability have been absolutely rock solid. I cannot remember any time in the last two to three years that Lambda behaved weird or slow. Here is an example of one of our most used Lambda's.
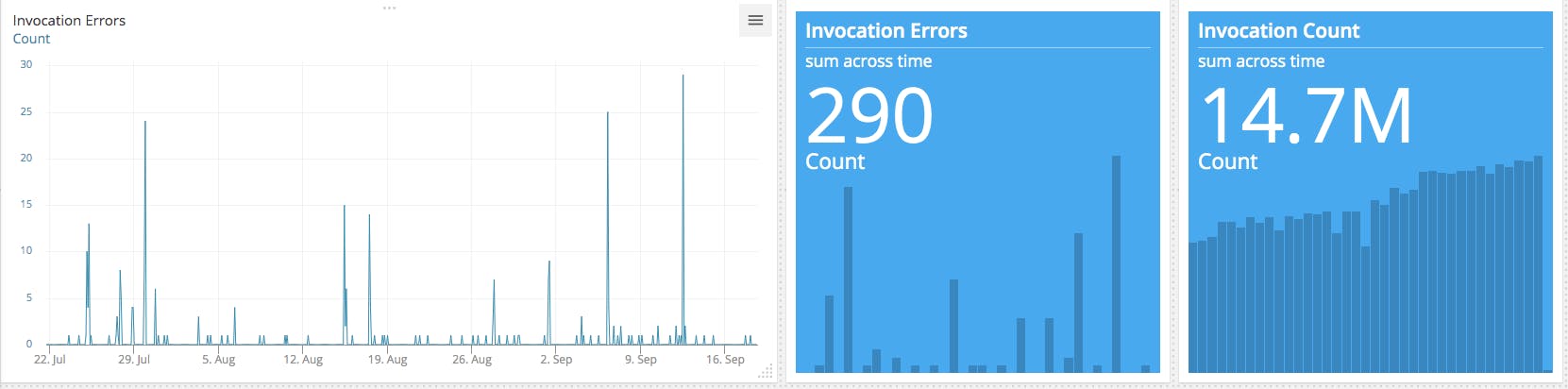
290 errors on 14.7M invocations. That's 0.0018%. And I'm 99% sure these errors were actually caused by some screw up in an API this Lambda calls. Errors were retried by the by.
I tweaked our Check runner for browser checks quite a bit — it's a Lambda running a Chrome browser — and tweaking the memory and runtimes is seamless. Getting runtime metrics per invocation allow you to really quickly see if and when tweaks have the necessary effect or do nothing.
The monitoring (errors, invocations etc.) you get is sufficient for most and if you want more you have options to hook in X-ray. Of course, all of this integrates with the rest of the AWS Cloudwatch universe for graphing, dashboards and alerting. No extra services needed.
Specifically, for Checkly's check runners, the various AWS regions and complete feature parity between the Lambda service in these regions made deploying to a world wide service trivial.
This is way huger than it sounds.
Heroku gives you two regions if you're not in the "call us for pricing" private spaces. Google Cloud functions run seven regions. Azure Cloud Functions are only available in the US or Canada.
The logging is a bit shit but at least you can search them. The Cloudwatch Logs UI really needs an upgrade though. The "versions" and "aliases" feature feels like an after thought to manage roll back / roll forward.
✅ Carefree and rock solid once deployed
✅ Regional availability & great integration into Cloudwatch
✅ Scaling is 100% transparent. No sliders, no new plans. It will eat traffic.
⚠️ Logging is pretty terrible
Cost 💵
Developers are obsessed with money in general and cloud hosting bills in particular.
So let's break down the cost of a daemon process that ingests a queue because I have the most exact data on this. This daemon is a well defined sub system. written in Node.js that I could totally port to Lambda if I wanted. It runs on Heroku now though.
For Heroku, the cost is $7 per month. However, the upgrade path is bumpy.

✅ $7 is the price of admission to anything serious on Heroku. The power you get for that — although seemingly feeble at 512MB RAM and unspecified compute power — is pretty generous in practice.
⚠️ When the $7 dyno is not cutting it any more, the next stage is $25. There is no gradual scaling.
For Lambda, have a look at the sexy stats below. We process around 10M results per month now.
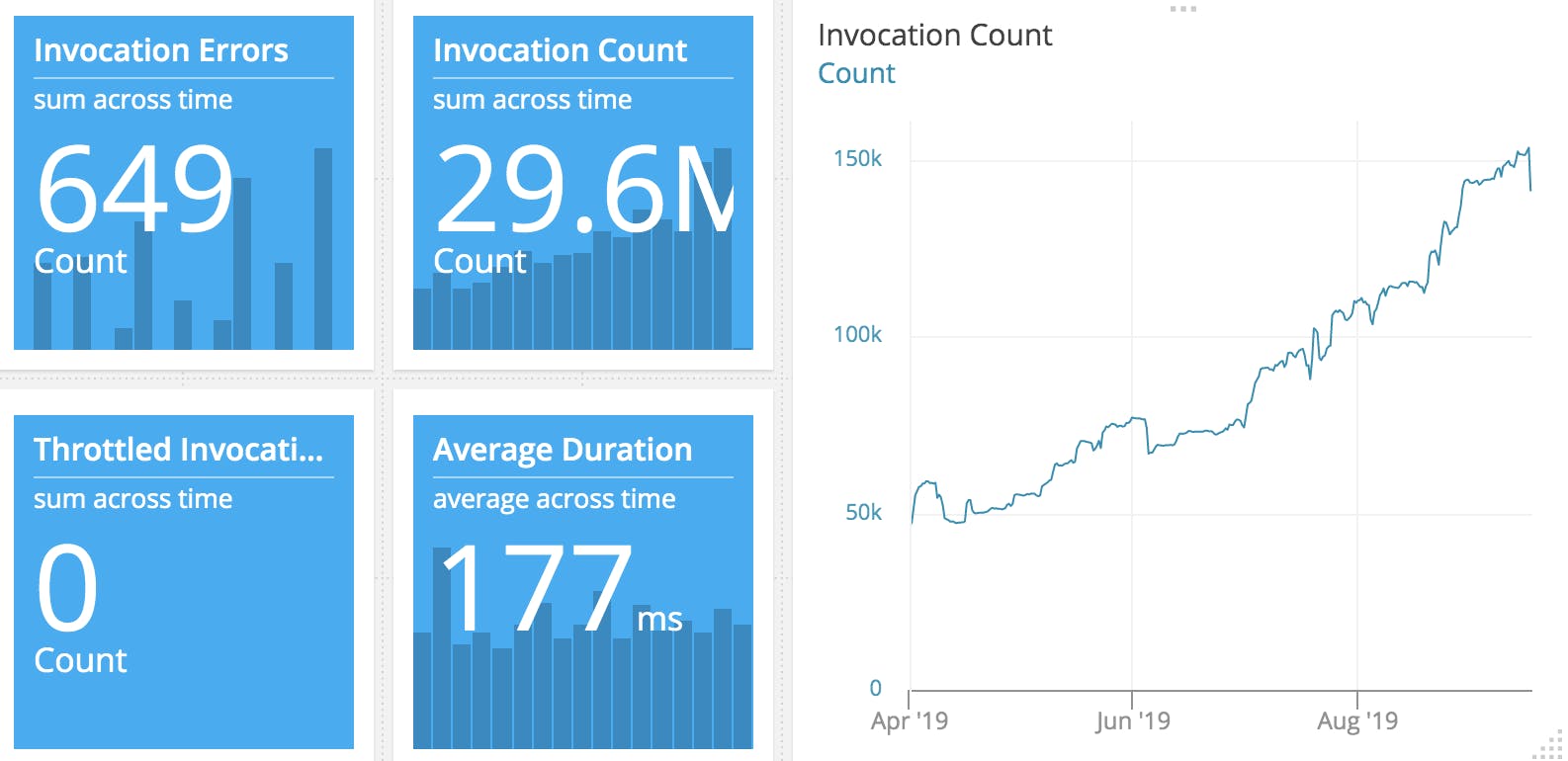
I ran the numbers using the dashbird.io Lambda cost calculator
10M * 128MB * 200ms = $6.17 a month. Add 21% VAT and you're at ~ $7,60
It's practically the same as Heroku. Sure, I can get the VAT back as a registered business. But remember, this number will only go up as Checkly grows.
If we use 512MB in this calculation — the same as the Heroku Dyno — the price goes to $18,67
Big caveat 1��
For other event driven daemons or workers, Lambda would most probably be cheaper. Certainly for low volume workflows like ingesting events from Stripe and Github.
It will be even cheaper when you stay inside the free tier. Example of doing 5M events per month using 128MB. Free tier on.
5M * 128MB * 200ms = $0.80 a month.
So what is the takeaway here?
Regardless of the actual out-of-pocket cost, AWS Lambda allows you experiment with new ideas with complete disregard for the cost. It frees you from discussions, budgeting and calculations. At least, to begin with.
✅ For low volume loads, Lambda is just incredibly cheap.
✅ It makes experimentation cheap.
⚠️ There is quite a clear cut off point where Lambda suddenly is just as or more expensive. This is not hard to calculate, but still.
Lock in 🔐
Vendor lock in is a myth.
At least on the web, HTTP and most application layers. The real lock in comes from choosing your database, queue providers and application frameworks. Refactoring that will take ages. Porting a Lambda to Google Functions or just bare metal will be easy in comparison.
Contrary to what many believe, Heroku score extremely well in the vendor lock in department.
The Checkly API and the daemon processes are deployable to any vendor with less than two hours of refactoring of which 1.5 hours struggling with the exact YAML format of the new vendor.
Also, our Heroku Postgres database is just a Postgres database. It could run anywhere. Same goes for the Heroku Redis instances.
For AWS Lambda — also somewhat surprisingly — the lock in is manageable. Again, make sure to keep your business logic separate from any Lambda magic and you can probably port over your function quite easily to either a traditional "serverful" solution or some other FaaS provider.
Getting rid of that specific SDK call that talks to AWS SQS and its specifics will be more work.
banner image: detail from "Goten-yama hill, Shinagawa on the Tōkaidō". Katsushika Hokusai, ca. 1832, Japan. Source




