

This is the second part of our 12-day Advent of Monitoring series. In this series, Checkly's engineers will share practical monitoring tips from their own experience.
We encountered a tricky issue with our public dashboards: they were experiencing sporadic outages, happening about once every two days. The infrequency and unpredictability of these outages made them particularly challenging to diagnose.
Our Hypothesis
Initially, we tried to correlate the outages with our logs, looking at the failure times reported by our browser check failures. Unfortunately, this method didn't yield any useful insights.
This is when we tried to use high-frequency API checks, running every 10 seconds. Our existing setup involved a browser check that ran hourly, which was sufficient under normal circumstances but not detailed enough to catch these intermittent issues.
ChatGPT to the Rescue
The issue with our public dashboards is, of course, already fixed for a long time, so to simulate a similar scenario I used ChatGPT4 to generate a simple nodeJS server for me using the following prompt:
Write a simple nodejs based rest endpoint that always returns a body "OK" and
a 200 status code without using a framework.
The endpoint should return right away.
There should be a loop that runs every 10s and with a 0.1% chance,
will cause the endpoint to return HTTP 500 for a time window of 30-60 seconds.
Afterwards it will go back to returning 200.Now all I had to do was to save the resulting code to a file and then run it with NodeJS. To publicly expose it for testing purposes a simple
ngrok http 3000was the perfect solution.
Configuring API Checks with Checkly
Next, I configured two API checks with Checkly, one running every 5 minutes and one running every 10 seconds.
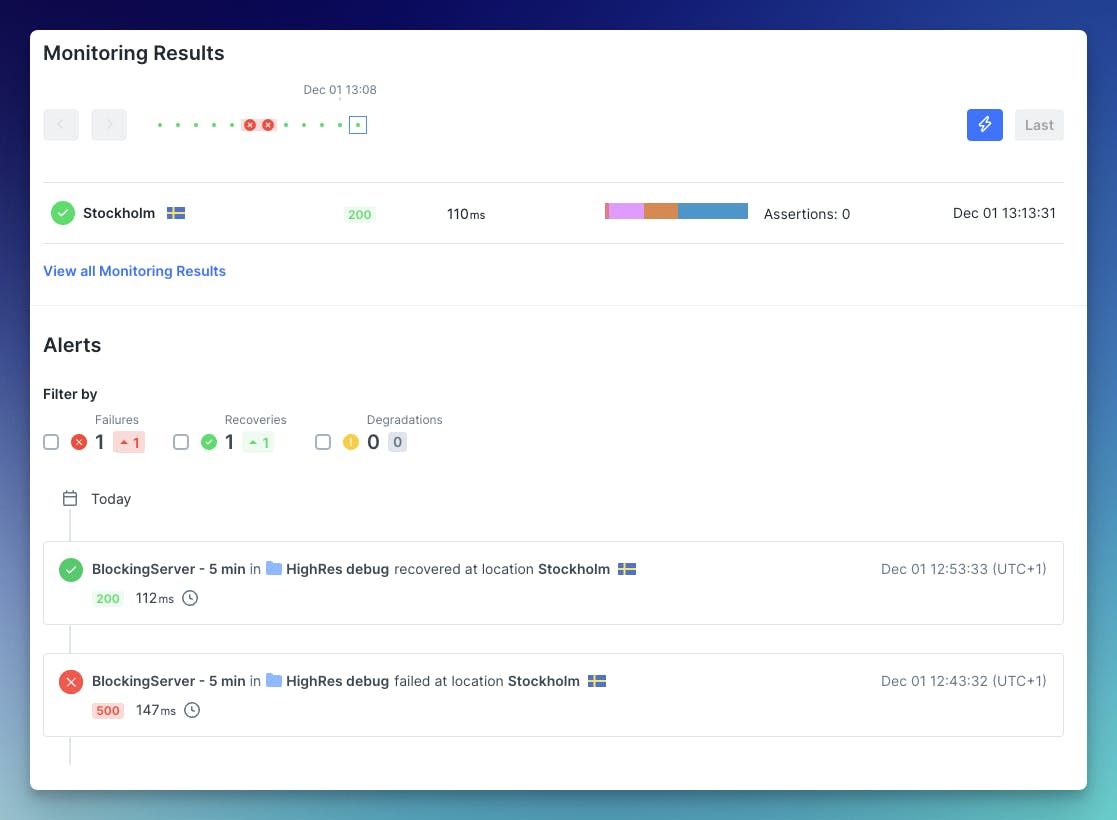
The screenshots really illustrate the benefits of temporarily or permanently using higher frequency checks. The 5 min frequency check did not detect all the error windows, and also does not help with understanding how long the service was down. Things might seem much better here compared to when you start probing the API every 10s.
5 minutes:
10 seconds:
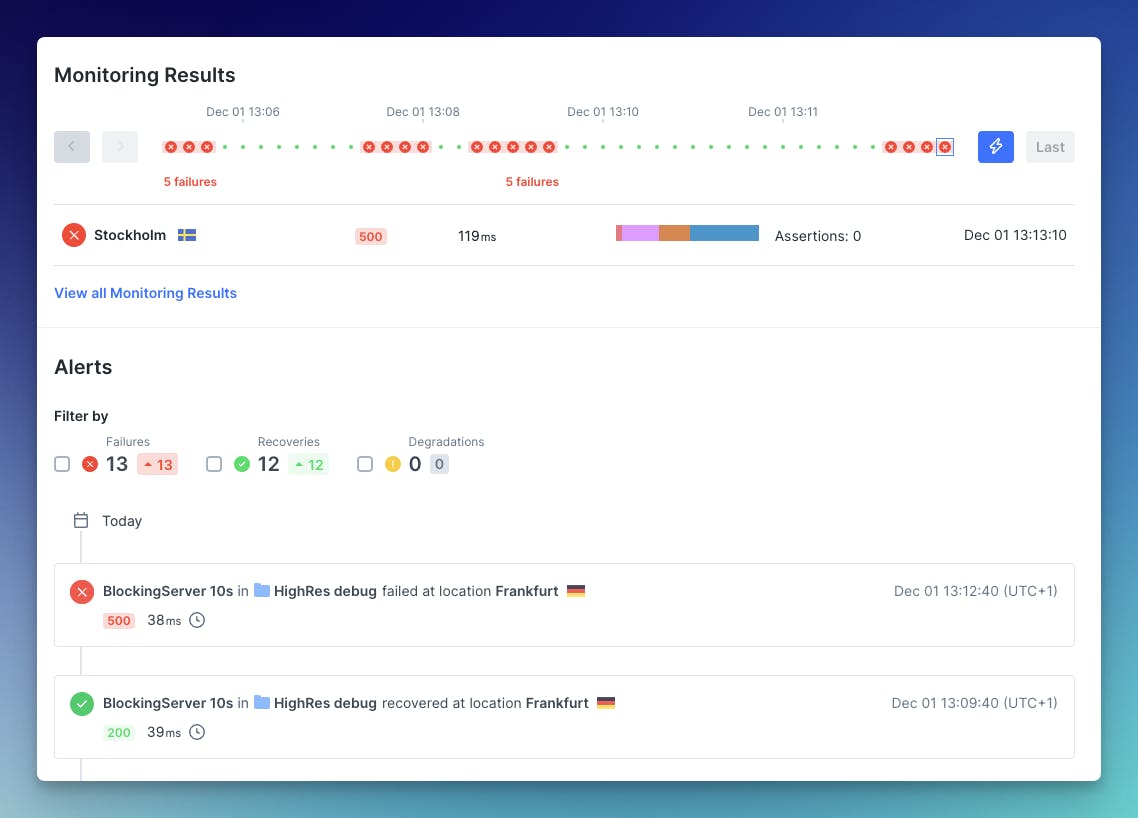
The results are quite revealing. The high-frequency API check shows almost exactly when the issue started, when it stopped and how long it took. It identifies all the 30-60s random errors. In real-world scenarios, this makes it much easier to find the correct logs and more importantly, also understand how big the problem actually is.
By leveraging Checkly's API checks for high-resolution failure timing, we were able to identify and subsequently address a problem that our standard monitoring approach had missed. This experience underscored the importance of synthetic monitoring with higher frequency checks, especially for issues that occur sporadically. With Checkly's help, we were able to root cause and fix the dashboard's sporadic outages and could enhance the reliability of our service.