

Table of contents
I am happy to announce that Checkly now supports parallel scheduling as a new way to schedule your checks.
Parallel scheduling allows you to reduce mean time to detection, provide better insights when addressing outages, and give improved accuracy in performance trends, making it a powerful new feature for all Checkly users.
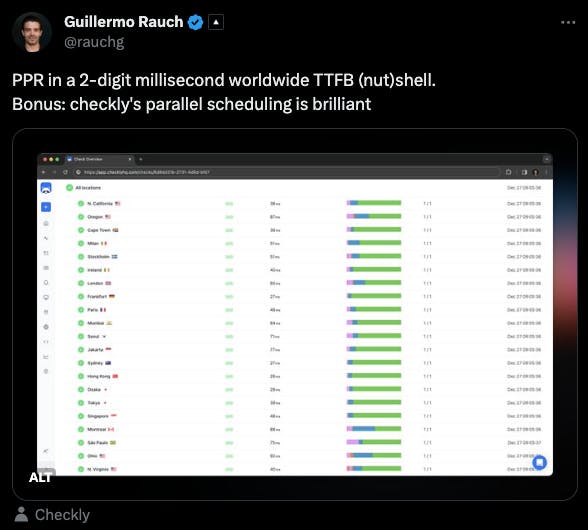
Source: Guillermo Rauch's X account
Parallel scheduling vs. round-robin
If you provide a service to users worldwide, you typically want to monitor it from several locations to ensure global availability. For most of Checkly’s history, we have run checks in what is known as a ‘round-robin’ pattern. In this case, a single monitor sequentially checks your application from various geographic locations, one after the other.
While this method provides a broad view of performance, it has limitations regarding time efficiency and real-time problem detection.
Ensuring minimum availability for global services with round-robin
In our example, we’ll consider a service used by a global audience, such as Vercel or Checkly. To ensure minimum availability, we create a check that monitors this service from locations around to world, ensuring coverage similar to the user base. In this example we pick the follow locations:
- Frankfurt
- London
- North Virginia
- Ohio
- Tokyo
- Sydney
This check is scheduled to run once every minute.
With the round-robin scheduling method, the check will execute from Frankfurt and then rotate through all the other five locations before returning and checking from Frankfurt again. This leaves a six-minute window where the service might be unavailable from that location without triggering any alerts.
The above highlights the problem with round-robin scheduling - while it can cover all the locations a service should be available from, the execution pattern leaves gaps where a regional outage might occur without the service alerting. The more locations you want to monitor, the greater the risk of a delayed alert
Parallel scheduling to close the gap
While the round-robin solution is decent, we still need to cover regional outages.
The solution is simple: Parallel scheduling. Compared to round-robin, parallel scheduling provides four main benefits:
- Reduced time to detect issues.
- Immediate insight into the scope of an outage.
- Increased chance of catching regional outages.
- Improved data granularity.
Parallel scheduling | Round-robin | |
Mean time to detect regional issues | No longer than the check frequency | Check frequency * number of locations monitored |
Check run data provided | You immediately know how many locations failed and where | You only know that at least one location failed |
Likelihood of detecting intermittent regional outages | High chance, since each location is checked at each check run | Medium to low, depending on the number of locations the check rotates through |
Data granularity | High—get data from each location at each run, and clearly see regional differences in performance | Medium—clearly see if the overall performance of a service degrades over time, harder to identify local problems |
With parallel scheduling, a check is scheduled and runs on each location configured. In our example from earlier the check would run from all six locations every minute and alert as soon as a location reports a failure. This can reduce the time to detect any regional issues by up to a factor of six since we are using six locations. For critical services and user paths, this will significantly affect both customer happiness and ensure SLOs are not broken.
The more locations you monitor, the more you can reduce your MTTD, potentially by a factor of 20.
Additionally, running a check in parallel gives you an immediate understanding of the scope of the problem - is it a global outage, or is it limited to one or two regions? This information can help inform the urgency of the problem and give you some idea of where the problem might lie.
Parallel check runs also reduce the risk of missing a short regional outage. In our earlier example, if the service would be unavailable from eu-central-1 for four minutes while the check was running from other locations this outage would never be registered. With parallel scheduling, catching these shorter outages becomes much more likely.
Finally, a check running in parallel from multiple locations will give you an accurate performance measure from all selected locations each time the check runs, giving you clear signals if a specific location has performance problems.

Using parallel scheduling in Checkly
Parallel scheduling is now available as a scheduling option for API, Browser, and Multistep checks. To select a scheduling strategy, edit your check and go to ‘Scheduling and Locations’:
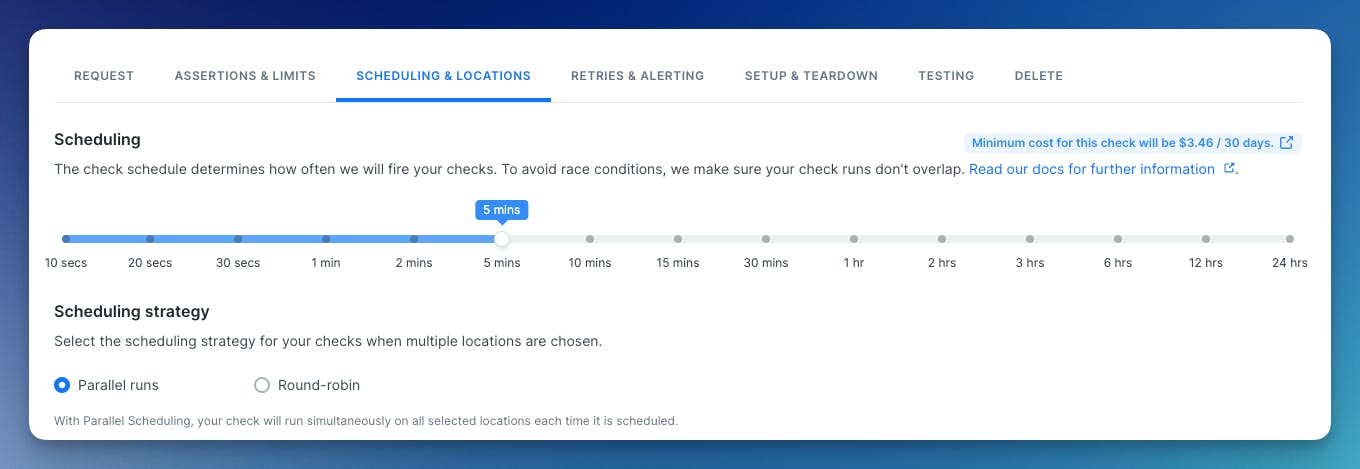
When using our CLI, or the Terraform provider, determining the scheduling strategy is done in the check construct.
CLI, notice the runParallel: true
new ApiCheck('list-all-checks', {
name: 'List all checks',
activated: false,
muted: false,
runParallel: true,
locations: ['eu-north-1', 'eu-central-1', 'us-west-1', 'ap-northeast-1'],
frequency: Frequency.EVERY_10S,
maxResponseTime: 20000,
degradedResponseTime: 5000,
request: {
url: 'https://developers.checklyhq.com/reference/getv1checks',
method: 'GET'
},
})Terraform, here we use run_parallel = true:
resource "checkly_check" "list-all-checks" {
name = "List all checks"
type = "API"
frequency = 0
frequency_offset = 10
activated = false
muted = false
run_parallel = true
locations = ["eu-north-1", "eu-central-1", "us-west-1", "ap-northeast-1"]
degraded_response_time = 5000
max_response_time = 20000
request {
method = "GET"
url = "https://developers.checklyhq.com/reference/getv1checks"
}
}For more information on how to use our CLI and Terraform provider, check out our docs.
Parallel scheduling and cost optimization
Finally, I want to discuss how parallel scheduling affects your costs when using Checkly. Each check run from a location counts against your total usage, so excessive usage of parallel scheduling can increase your usage amount above your budget.
In order to help you understand how the different check settings affect your final cost, we have added a helper in the check editor, giving you a clear indicator of how the number of locations and the check scheduling method changes the monthly cost.
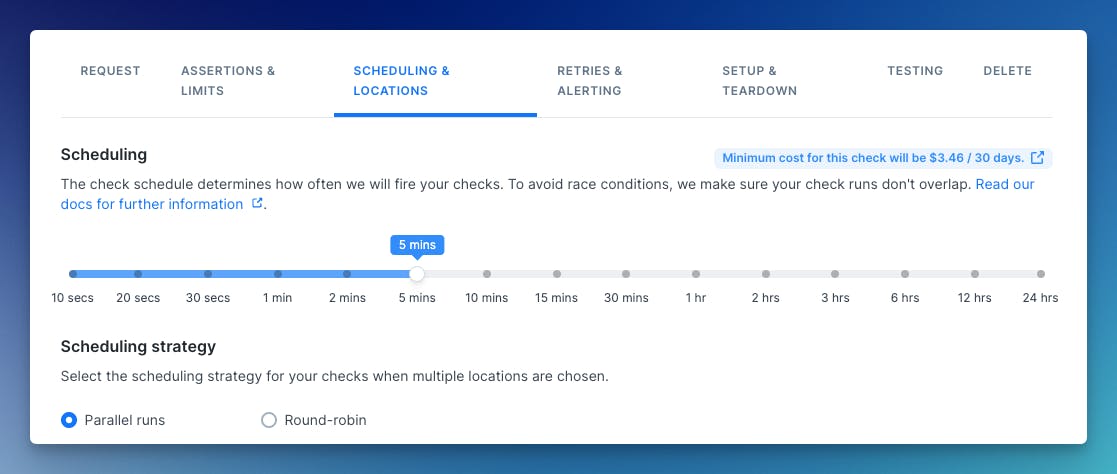
Do note that this helper only provides an approximation and that the final cost can end up being higher in case the check uses a lot of retries.
I recommend using parallel scheduling for your critical services and flows, where downtime costs money and user happiness, and using round-robin scheduling for your less critical monitoring, where some downtime can be accepted.
If you want more details on how check costs are calculated, we have a detailed breakdown in our documentation.
Parallel scheduling is available now on all Hobby, Team, and Enterprise plans.