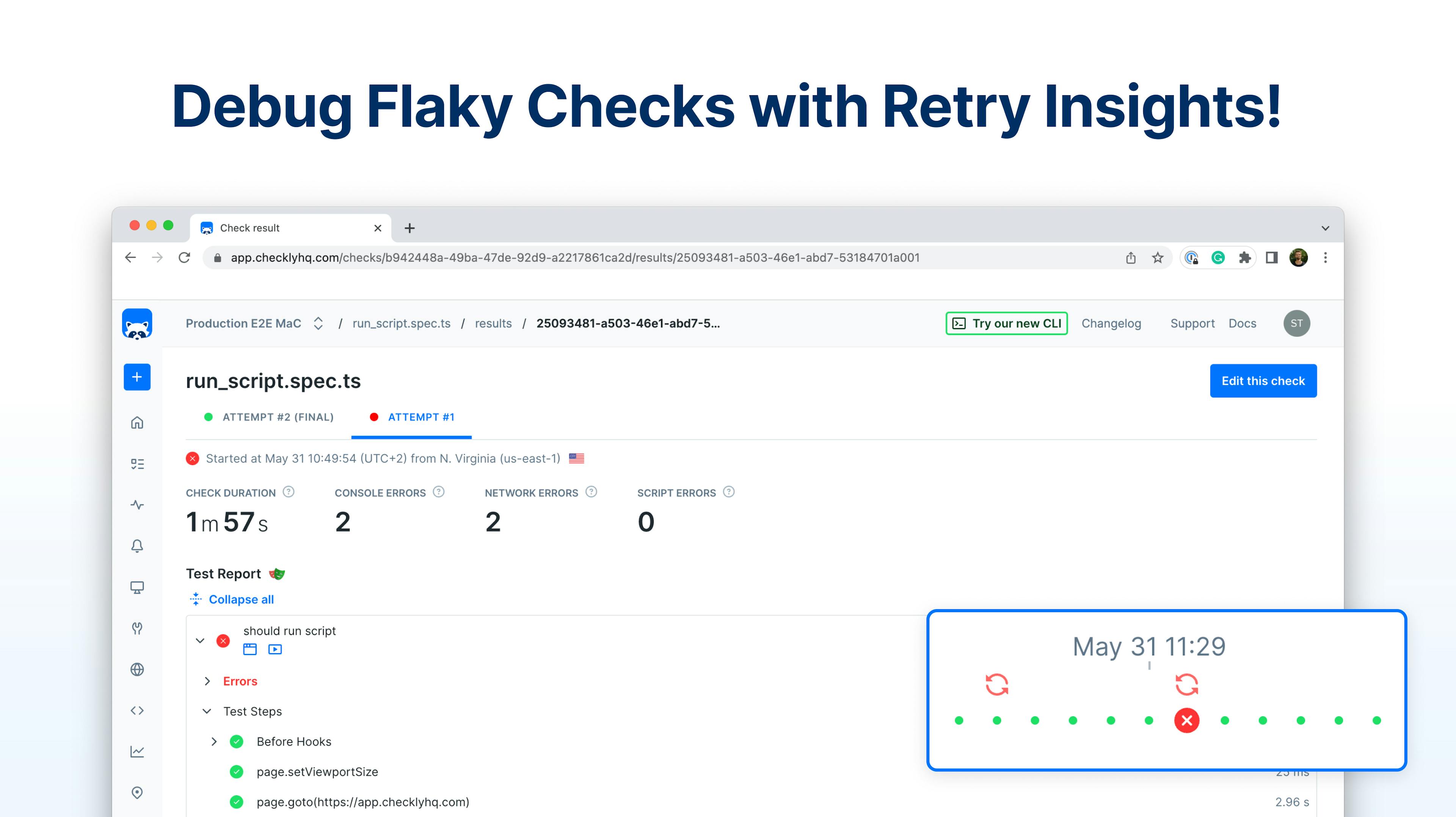
Welcome dear reader! It's time for a deep dive into the world of DNS. As you would expect for a SaaS startup, everything starts with the customer. On a bright sunny day, we received a support request, asking for an explanation for unusual 5 second DNS resolution times that triggered check degradations.
It seemed that for some reason, sometimes, there were >5s resolution times for the DNS resolution of that check. That was definitely too slow, so something was obviously wrong. We got in touch with NS1, the DNS provider that was responsible for the authoritative servers of this domain, but they told us everything was fine according to their monitoring. It was clear that something in between NS1 and Checkly was not working as expected.
So let’s dig a little deeper and figure out what was going on and what to do about it.
💡 Nerdbox: This article contains nerdboxes with very low level technical details. You can skip them and still understand the article just fine or nerd out with me about those details in the Checkly Slack Community.
How big is the problem on the platform?
Before we rush into solution mode, let’s take a step back and see how big the problem is, to understand what priority it should have. I used our data lake to pull 5 months worth of API check run information and find out how many >5s DNS resolution times we had since September of last year.
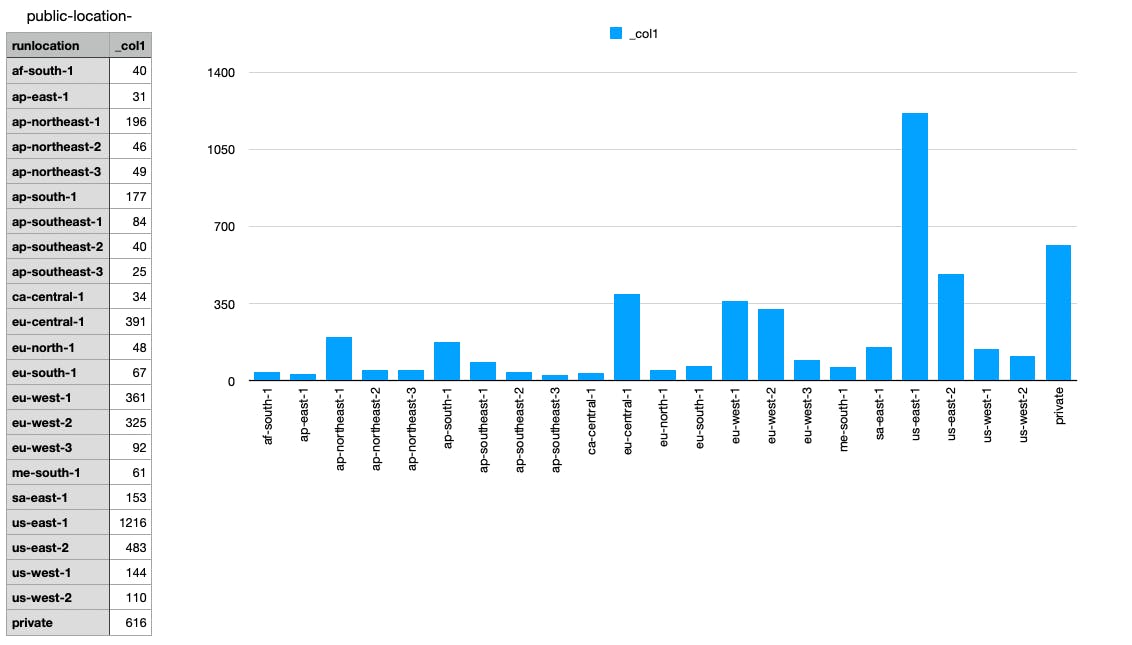
We notice a couple of interesting things in the data:
- We see ~4000 timeouts compared to 1.2bn total API check runs, that means it happens very rarely - and that means: it’s not a critical incident. 😅😮💨
- us-east-1 does seem affected more than other regions, but also runs significantly more checks than other regions, and compared to the total amount of check runs this will probably even out, so this chart might be a little misleading
- Private locations have an unusually high amount as well, so while it’s not a proof, it strongly suggests our AWS infrastructure is not the culprit. There probably is something in our NodeJS backend causing this.
Anyway, the platform is not on fire, which is good. So let’s investigate! 🕵️♀️
How do you debug a DNS problem?
Bisecting the problem
My default tool to debug production issues would usually be Checkly, but our API checks were never designed to provide deep insights into DNS resolution. They only give you basic timing information that we are getting from the NodeJS request library. This is good for pointing out when there is a DNS problem for synthetic monitoring, but it does not really help you debug it. The first step of this investigation was to refresh my memory about how NodeJS and request actually do DNS resolution and measurements.
After checking the code I was sure that the request library implemented DNS timing measurement properly. It properly calculates the time difference between opening the network socket and getting a DNS resolution. With request out of the picture, I analyzed the Checkly application code and found that it did not do anything on top of what request gives us. I concluded that the problem was not in our code base or in the library, so it must be something else.
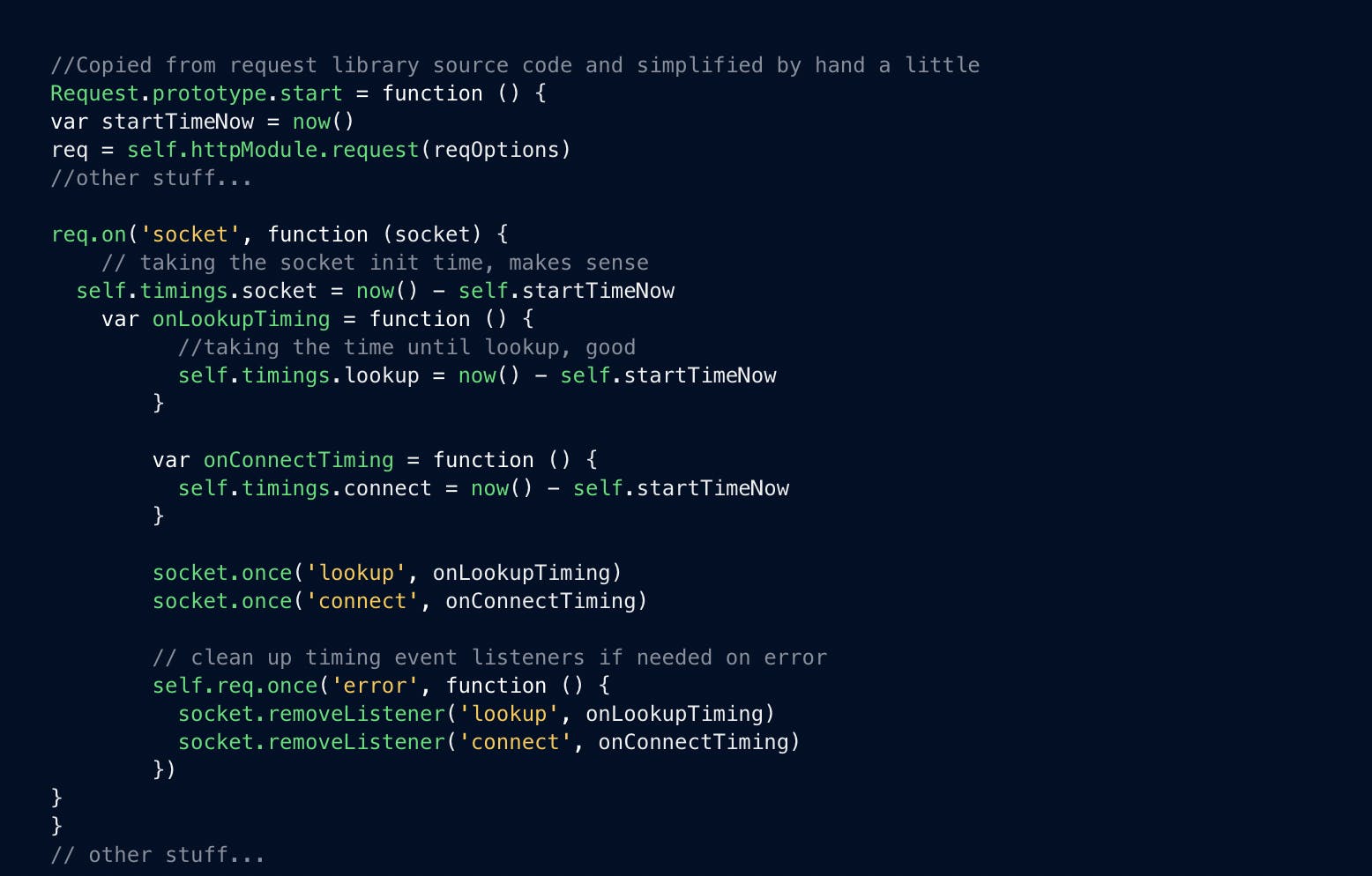
💡 Nerdbox: How does requests calculate DNS lookup time you ask? Understanding code is not limited to GPT-3, so let's take a look! In the simplified code snippet below you can see that the request library is doing it just right. They are using proper absolute time and not wall clock time for this, which is good. The math is also correct, calculating the difference between socket creation and lookup response, it all seems solid. Note: I was using request 2.88.2 for this, newer versions might do this differently.
//Copied from request library source code and simplified by hand a little
Request.prototype.start = function () {
var startTimeNow = now()
req = self.httpModule.request(reqOptions)
//other stuff...
req.on('socket', function (socket) {
// taking the socket init time, makes sense
self.timings.socket = now() - self.startTimeNow
var onLookupTiming = function () {
//taking the time until lookup, good
self.timings.lookup = now() - self.startTimeNow
}
var onConnectTiming = function () {
self.timings.connect = now() - self.startTimeNow
}
socket.once('lookup', onLookupTiming)
socket.once('connect', onConnectTiming)
// clean up timing event listeners if needed on error
self.req.once('error', function () {
socket.removeListener('lookup', onLookupTiming)
socket.removeListener('connect', onConnectTiming)
})
}
}
// other stuff...
// Later in the code, these values are used for giving you back your timingPhases
// This is how you do it! We get the correct time from when
// the socket was created till the lookup was done.
// Nothing to complain, move on people.
response.timingPhases = {
wait: self.timings.socket,
dns: self.timings.lookup - self.timings.socket,
tcp: self.timings.connect - self.timings.lookup,
firstByte: self.timings.response - self.timings.connect,
download: self.timings.end - self.timings.response,
total: self.timings.end
}
Product Research: How would you build a proper DNS check?
The next question I asked myself was: How would you build a good DNS check that can actually show you what’s going on?
Of course there is the obvious simple probe that just does a DNS resolution against a public DNS server like, for example, Google’s 8.8.8.8 recursive DNS and measures time. But this doesn’t help you much, because Checkly already offers that with API checks. Luckily I had the pleasure of getting some great insights from the helpful support folks at NS1. They have a great blog post that explains how DNS basically works, which I encourage you to read. Their advice to implement a full DNS check was to “simulate” what a public DNS server like the Google DNS does. Like me, you probably don’t remember the details, so here is a rough outline of how such a "simulated" DNS check would work for a domain like f.ex. checklyhq.com :
- Query a root DNS server to get all TLD servers —> root servers know the IPs of TLD servers
- Pick a TLD server for the .com domain —> TLD servers know the IPs for servers knowing where all the domains of a top level domain are
- Send a query to that TLD server for checklyhq.com to get the authoritative DNS for the checklyhq domain —> the authoritative servers (like NS1) know the IPs of concrete domains (like checklyhq)
- Send a query to the authoritative server and voilá, get the IP back as a response
- Log and measure everything as you go
This gives you a full picture of the entire resolution process. If you want to try it yourself, the command line tool dig is a great option. Run dig +trace checklyhq.com to get the output of the above process. You can also use dig to make a simple DNS resolution call to the recursive resolver (Google DNS in this case) like so: dig @8.8.8.8 checklyhq.com.
Building a quick DNS Check with NodeJS and Dig
I wanted to try a quick implementation of this. Since Checkly is a NodeJS company, I tried using the NodeJS dns package first. Unfortunately, all you will see when making a DNS query to a root server is an ENODATA error. I found this issue thread https://github.com/nodejs/node/issues/33858 and it became clear that NodeJs would not be able to help me here. I guess this was never implemented, because nobody really needs this unless they want to build DNS monitoring with NodeJS, which admittedly, is probably not the primary use case anyway.
💡 Nerdbox: How does NodeJS DNS resolution actually work? This might be surprising, but NodeJS actually has 2 distinct ways to resolve DNS. In the red corner, you have DNS.resolve which is using the C-Ares (https://c-ares.org/) library to resolve DNS. It is an asynchronous C library. And in the blue corner, you have dns.lookup which uses the blocking https://man7.org/linux/man-pages/man3/getaddrinfo.3.html getaddrinfo syscall. Now, I wonder what would happen if you executed a lot of queries with either function and compared the impact on the libuv thread pool & nodejs performance…but maybe I’ll keep that for next time. 😉 PS: If you want to impress people at parties with your wicked NodeJS DNS knowledge, check out the docs: https://nodejs.org/api/dns.html#implementation-considerations
So I was back to using dig. Luckily there is the node-dig-dns package, that runs the dig binary and parses the output into a nice JSON object. With this I could write some nice code like below:
const dig = require('node-dig-dns')
const domain = 'checklyhq.com'
// A query to the root DNS
let response = await dig(['-4', '.', 'ANY'])
console.log(response.time)
...
// a query to the com TLD server, forcing IPv4
response = await dig(['-4', rootA,'com.', 'NS', 'IN'])
const tldServer = response.additional.find((s)=>s.type==='A')
//getting the authoritative name servers from the TLD server
response = await dig([ "@"+tldServer.value, domain, 'NS'])
and so on...After some coding I had a nice little tool that I could run in a loop and see if I could reproduce the problem locally or on AWS in isolation, to really make sure it wasn't anything our backend did.
The tool does the following on each iteration:
- A simple resolution using dig against Google
- Runs an isolated code snippet taken out of our backend code to get request timings, just as in Checkly
- A full traceroute
- A full DNS trace using dig
Next, I ran this on my local machine and on a couple of lambda functions in different regions, for 32k times in total, over a couple of days and was not able to get a single 5s spike. Of course.
While all of this was running, I decided to also set up a private location on my local Linux laptop as initially I could see that private locations were also affected quite a bit.
Reproducing things that almost never happen with Checkly
By now I already had a suspicion what could be the cause of this issue, but I wanted to be sure. I still had to reproduce it. Checkly makes analyzing occasional problems like this really easy because you can go as high as running checks every 10s. Additionally, Checkly supports sending email alerts when an API check degrades (is slower than 5s). I created a check and an alert on my private location and then waited.
I got my first spike after roughly 12 hours! That is nice, the issue is reproducible! But how do we figure out what is going on here?
Set up tcpdump on a private location and wait some more
With a way to reproduce it, I started tcpdump which is a Linux command line tool to dump the entire network traffic of a system as a pcap file, for later analysis with WireShark. After waiting another day, I was able to finally capture an occurrence.
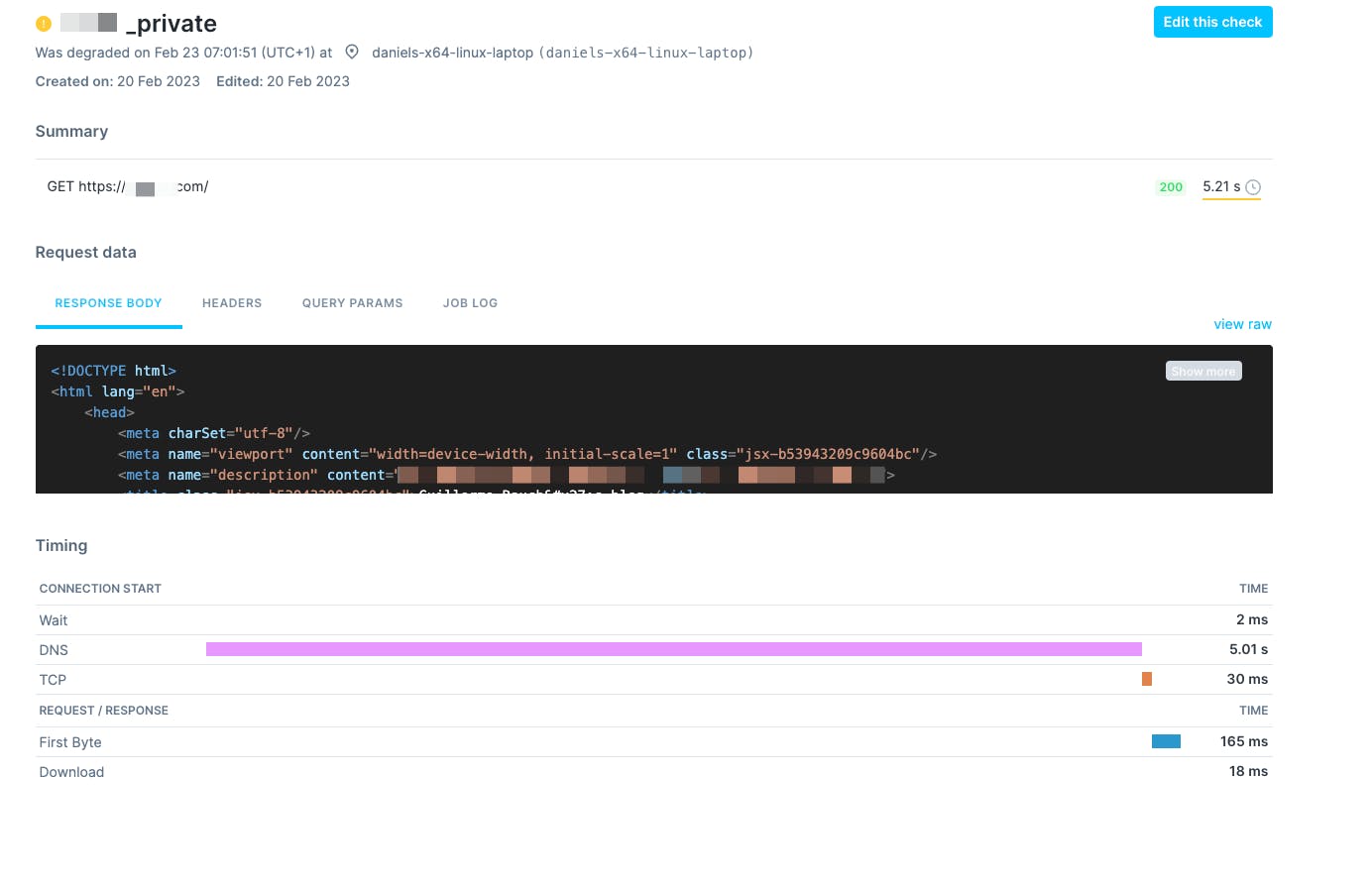
Very excited I rushed to my laptop, downloaded the pcap from my Linux box, and skimmed through all the DNS requests. The timing information on Checkly perfectly matched the Wireshark capture and here we can see the culprit:

Two DNS queries happening 5s apart and the response coming in right after the second query. So this is obviously a retry timeout! 🥳 If you’re still not sleeping or watching TikTok videos on the side, pretending to be still reading this article, you might wonder too, why does dig never have this problem but NodeJS does? I did not see one 5s spike in any dig query.
For our NodeJS code, the case is clear. If you think back how the request library calculates DNS timings, then it is obvious why we see 5s +x ms query timings. The retry happens in lower levels and the node library simply does not know about it. It can only measure the time from starting the request, to when the hostname is resolved, which includes the 5s timeout.
The first query ran into a timeout because an UDP packet was lost, but the second query went as fast as usual, so the query time is actually ok! When running dig with time we can see how it behaves differently. See below:
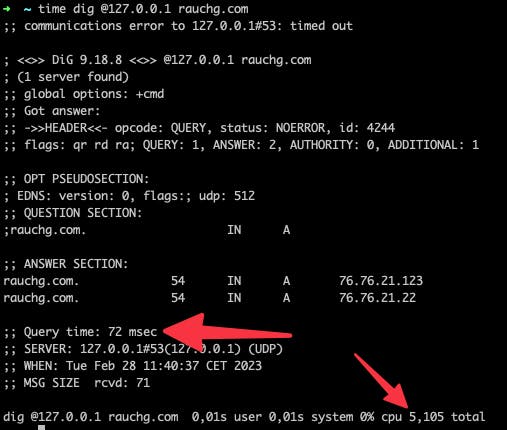
The Dig command ran for 5s, but the Query time is only 72ms. Seems like it just ignores the first try and only reports resolution time of the successful DNS resolution. Well played dig. Well played indeed.
Now for the fix!
The first question for me was, of course, what would a fix be? Technically, nothing is really broken. UDP packet loss just happens, it’s a natural phenomenon, there’s the birds and the bees and there is UDP packet loss. We cannot really fix anything and NodeJS does not allow us to ignore retries like dig does.
The bigger problem is that Checkly sends degradation alerts after 5s by default. Combined with a 5s DNS timeout, this is problematic. In addition, for a REST API check, UDP packet loss is not really relevant information. While in general I can see scenarios where you would want to monitor how many UDP packets get lost in a network of course, REST API checks are not the right tool for that. And lastly, even though this only happens like 15 times a day on the entire platform, and we have automatic retries in place that will probably swallow 99%+ of those 15 times, I cannot shake the feeling that some poor on call engineer like myself gets woken up in the middle of night as a consequence of one of these failures.
For reasons that are hopefully understandable to you, my dear readers, I did not want to wait 12 hours for packet loss to happen again. That’s why I needed an easy and quick way to set up a “chaos” DNS server proxy. Luckily someone wrote a little Python script some years ago to do this. I forked the repo and quickly updated it to run on Python3 (https://github.com/danielpaulus/slodns) as I figured installing Python2 on a Mac would have probably taken me twice the time. 😂😭
Next, I fired up sudo python3 slodns.py -d 0 -p 53 -l 33 to have a local UDP/DNS proxy with no -delay, that runs on -port 53 and has 33% of packet -loss. You need sudo here of course because 53 is a privileged port. With the chaos proxy in place, I could see that the issue was reproducible. My test tool showed that NodeJS resolution was very sensitive towards these timeouts while dig was not.
As expected, the nodeJS resolver showed timeouts of multiple of 5s whenever the proxy would drop a packet while dig just showed the successful resolution time. Unless you hit the max number of retries dig has configured, then it returns null.
Of course it is perfectly reasonable for a software engineer to produce a 2.5k word write up, spend days on analyzing network communication and creating tools, to eventually change 2 lines of code. So here is what eventually got merged to our Github:
const dnsFunction = function (ip,args, cb) {
// choose a different timeout than 5s here
// 4 tries is the default
const myResolver = new dns.Resolver({timeout: 5000, tries: 4})
myResolver.setServers(['8.8.8.8'])
return myResolver.resolve(ip, function (err, ips) {
if (err) {
return cb(err)
}
return cb(null, ips[0], 4)
})
}
//set the function as lookup in your request config object
const requestConfig = {
lookup : dnsFunction,
.... other options
}It's rolled out for the customer who had the problem originally and I will observe the effects of this change on the platform, so that we can roll it out for everyone eventually. So far it seems like it did the trick as no further 5s DNS resolution spikes were seen.
Now, I need to keep pushing our product managers to prioritize building DNS checks.
Thanks for reading! You can also follow me on Twitter at @Daniel1Paulus.
PS: Here is all the WIP code: https://github.com/checkly/dns_debug_script It's hard to read and hacky, so use at your own risk!