

Let’s face it. Incidents will always happen. We simply can’t prevent them. But we can strive to mitigate the impact incidents have on our product and customers.
Ensuring high reliability depends on quickly and effectively finding and fixing problems. This is where the metric MTTR, standing for “mean time to restore” or “mean time to resolve,” becomes valuable for organizations. It allows them to quantify the duration needed to address an incident or reinstate a service following its report.
Through practical advice and best practices, the article aims to guide IT and DevOps professionals on systematically reducing MTTR and enhancing their organization's resilience and service quality.
What is Mean Time to Repair (MTTR)?
MTTR, or Mean Time to Repair/Restore/Resolve, is a critical performance metric used to quantify the average time required to fix a failed system/component, or to restore a service after a disruption.
In addition to reflecting a team's ability to respond to and resolve issues, MTTR is a critical indicator of the effectiveness and efficiency of maintenance and repair processes. It also identifies areas where processes can be improved.
By examining MTTR, companies can find operational bottlenecks, optimize their response plans, and ultimately improve overall service reliability. In industries where uptime is critical, like finance, e-commerce, telecommunications, etc., lowering MTTR is a top priority to preserve competitive advantage and customer satisfaction.
Why should you care about MTTR?
MTTR is a metric that directly impacts the operational efficiency, customer satisfaction, and financial health of an organization.
Here are some key reasons why MTTR should be a focal point in your organization:
- Increased availability and reliability: In the event of a breakdown, systems, and services are restored faster when the mean time to repair (MTTR) is smaller, guaranteeing greater availability and dependability. Maintaining continuous operations is crucial, particularly in sectors where downtime might result in serious disruptions or safety hazards.
- Increased customer satisfaction: Extended or frequent outages can annoy clients, which may damage their confidence and, eventually, cause a loss of business. Organizations may improve customer satisfaction and loyalty by ensuring that their services are continually accessible by lowering MTTR.
- Cost savings: The cost of downtime is high. In fact, back in March 2019, Facebook (now Meta) lost an estimated $90 million due to a failure that lasted around 14 hours. And we’re talking about Facebook–an industry leader that can handle financial losses like these. What happens if a smaller startup faces a 14-hour outage. The impact could be severe. A failed system can result in lost income, waste of resources, and increased maintenance expenses with each minute of downtime.
In general, organizations with shorter MTTR can attract and keep clients more successfully than other companies with more prolonged downtimes by providing more dependable services.
How to measure MTTR
Divide the total amount of time spent on unscheduled maintenance by the total number of times your system has failed during a certain time period to get the MTTR. Hours are the most often used time element for the mean time to repair.

For example, one of your assets could have malfunctioned six times during the previous month. During this month, you spent a total of 12 hours repairing these failures. In this case, your MTTR is 2.
How to reduce MTTR
Reducing MTTR is almost always one of the key focuses of a DevOps team. Here are a few ways you can try to reduce MTTR/
Implement standard incident management processes
By establishing and combining standardized incident response rules, you can develop a comprehensive incident management framework. This should cover the full lifespan of a failure, from early discovery and timely diagnosis to effective repair and ultimate verification of resolution.
Having everything standardized, you'll help every team member know what to do when they encounter an error or a failure. Moreover, you'll enable new team members to understand how you handle incidents.
The ultimate objective is to keep operational continuity and satisfy consumers by minimizing downtime and promptly restoring services.
Improve skills and promote knowledge exchange
Focus on improving your team's skills with ongoing training. Use regular programs that cover new technologies and the best ways to solve problems. This will give them the skills they need and increase their confidence in dealing with tough issues.
Furthermore, fostering an environment where knowledge sharing is encouraged—through regular meetings, workshops, and digital platforms—ensures that valuable insights and solutions are freely exchanged among team members.
Creating a centralized knowledge base that is regularly updated and easily accessible can serve as a vital resource for quick reference, helping to significantly reduce the time needed to understand and address new or recurring problems.
Such initiatives not only contribute to a more skilled and adaptable workforce but also try to build a collaborative culture that values continuous improvement and collective problem-solving, leading to more efficient and effective incident management processes.
Cultivate strategic vendor and partner collaborations
Nurturing collaborations with vendors and external partners is key to decreasing MTTR, as it guarantees expedited access to specialized assistance and necessary replacement components.
Setting up service level agreements (SLAs) with stipulations for swift support and maintenance responses aids in hastening the remediation process. Moreover, proactive engagement with vendors to identify and address issues before they become significant can avert potential system failures.
This approach not only reduces periods of inactivity but also taps into the specialized knowledge of external entities, augmenting your team's capacity to efficiently handle and resolve incidents.
Implement proactive monitoring and alerting
Use advanced monitoring tools like Checkly to continuously oversee the health of your systems and services. Proactive monitoring can help detect issues before they lead to failures, allowing for immediate response. Automated alerting systems can notify the relevant teams about potential problems in real time, enabling quicker initiation of the troubleshooting process.
Checkly’s newest feature, parallel scheduling, directly reduces mean time to response, especially when it comes to services that need global coverage because it specifically detects regional outages.
Reducing MTTR with parallel scheduling and Checkly
To guarantee global availability, you would usually monitor a service you provide to customers worldwide from multiple locations.
Before launching parallel scheduling, we had a default scheduling strategy called “round-robin.” Here, a single monitor evaluates your application one after the other, consecutively, from different geographic regions.
This approach has limits with regard to time efficiency and real-time problem identification, even though it offers a comprehensive perspective on performance.
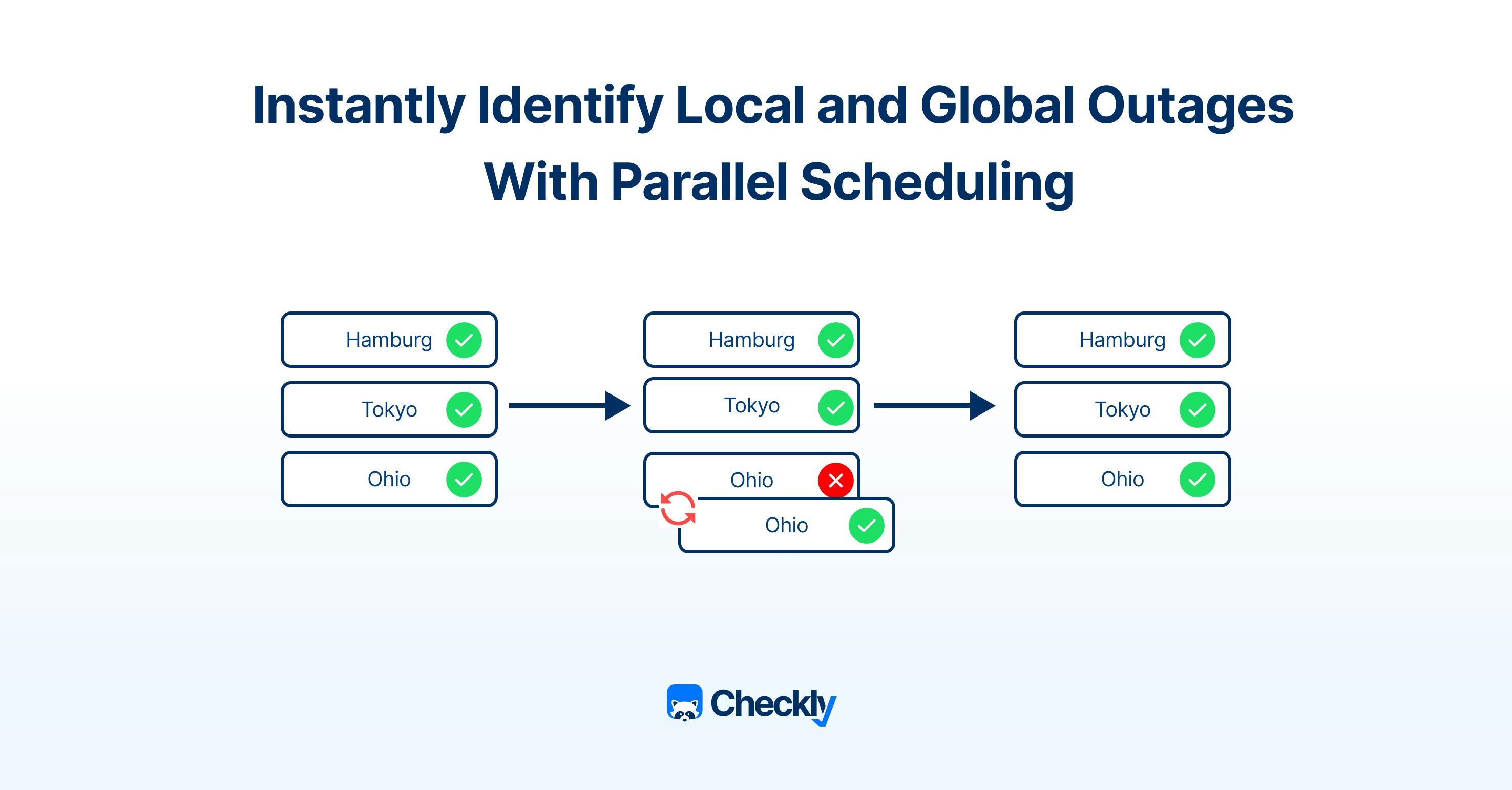
Let’s say we have a global service that we monitor each minute from the following locations:
- North Virginia
- Ohio
- Tokyo
- Sydney
If we monitor this service with round-robin, it will execute from North Virginia and then from the other three locations, one by one. This means that if it becomes unavailable in North Virginia one minute after it was checked, you won’t get any alerts. In this case, if you add more monitoring locations, you’ll increase the window where an outage might go undetected.
Parallel scheduling closes this gap because the check would be scheduled to run on each location each minute and trigger an alert as soon as a service fails. Because we rely on four locations, this can cut down on the time it takes to identify any local problems by as much as a factor of four. This will have a major impact on user paths and important services, improving customer satisfaction and guaranteeing that SLOs are met.
You can reduce your MTTR more by monitoring additional locations—up to a factor of 20.
Benefits of parallel scheduling
Parallel scheduling can address failures caused by wrong DNS configuration, CDN or server connectivity problems, regional network failures, etc.

You can quickly determine the scope of the issue by doing a parallel check: is the outage occurring worldwide, or is it just affecting one or two regions? You can utilize this information to determine the problem's urgency and to get a general notion of its possible location.
Additionally, parallel check runs decrease the chance of overlooking a brief regional outage. In the previous case, this outage would not have been recorded if the service from eu-central-1 had been unavailable for four minutes while the check had been carried out from other locations. Catching these shorter outages is significantly more likely with parallel scheduling.
Last but not least, a parallel check that runs from several places will provide you with a precise performance measure from each location you have chosen each time the check runs, letting you know whether a particular location is experiencing performance issues.
In fact, this feature is so good that even Gullermo Rauch, CEO of Vercel, likes it:
How to get started with parallel scheduling
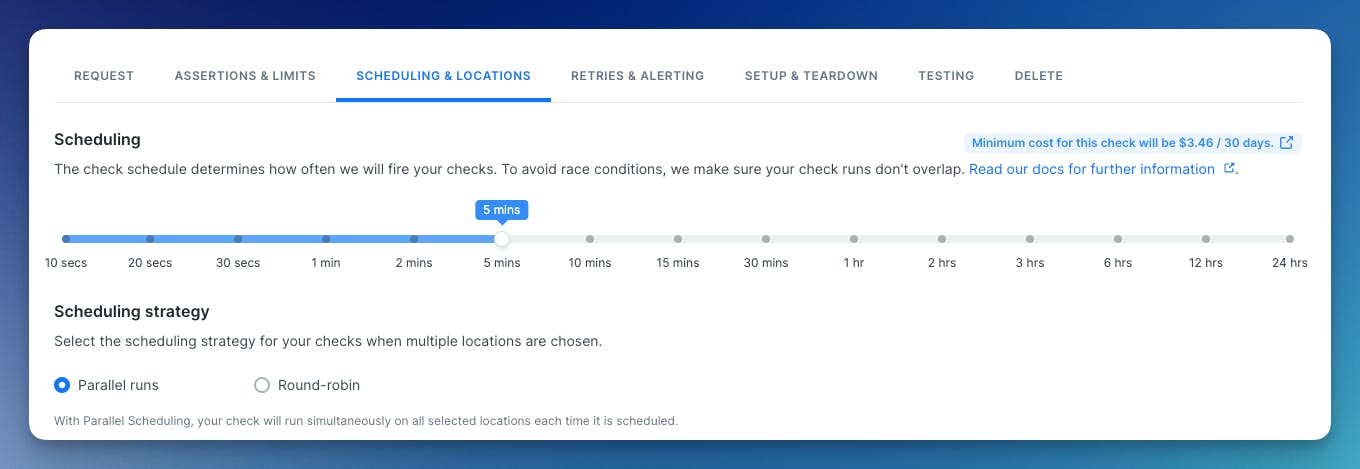
To select parallel scheduling as your check strategy, edit your check, go to “Scheduling & Locations,” and then select Parallel runs.
When using our CLI, or the Terraform provider, determining the scheduling strategy is done in the check construct.
CLI, notice the runParallel: true
new ApiCheck('list-all-checks', {
name: 'List all checks',
activated: false,
muted: false,
runParallel: true,
locations: ['eu-north-1', 'eu-central-1', 'us-west-1', 'ap-northeast-1'],
frequency: Frequency.EVERY_10S,
maxResponseTime: 20000,
degradedResponseTime: 5000,
request: {
url: 'https://developers.checklyhq.com/reference/getv1checks',
method: 'GET'
},
})Terraform, here we use run_parallel = true:
resource "checkly_check" "list-all-checks" {
name = "List all checks"
type = "API"
frequency = 0
frequency_offset = 10
activated = false
muted = false
run_parallel = true
locations = ["eu-north-1", "eu-central-1", "us-west-1", "ap-northeast-1"]
degraded_response_time = 5000
max_response_time = 20000
request {
method = "GET"
url = "https://developers.checklyhq.com/reference/getv1checks"
}
}Conclusion
The importance of MTTR as a metric extends beyond merely measuring response times; it is a comprehensive indicator of an organization's ability to maintain high service levels and minimize disruptions. By focusing on reducing MTTR, organizations not only safeguard their operational continuity but also reinforce their commitment to delivering quality service to their customers.
Checkly’s parallel scheduling not only speeds up the identification of problems but also ensures a more efficient diagnostic process by providing a holistic view of the system's status in real-time. Faster detection and diagnosis directly translate to quicker response times, crucial for minimizing downtime and maintaining high service levels.


