
Table of contents
Every time I share a project using SaaS tools, someone inevitably responds that they could do the same thing on their own home server ‘for free.’ I mention this not because it is annoying, since I would never go on social media at all if annoying responses were allowed to change my behavior, but because I think it points to a basic misconception that still affects DevOps practitioners today: the refusal to accurately estimate the real costs of self-managed solutions. Sure, we’re probably not going to run the company email server on a Raspberry Pi clone in the closet, and we don’t see DIY solutions as totally free, but there’s still an unwillingness to write down and consider the real costs. Wherever you run your service, a DIY option will always entail much higher operational and maintenance costs than infrastructure costs
Checkly is a good example of an ‘out-of-the-box’ SaaS tool that leaves you doing as little work as possible to set up heartbeat checks, synthetic user tests, and API pingers. Checkly is all about site reliability: letting you know that your service is working as expected for all users, anywhere in the world. I wanted to take some time to compare Checkly to creating your own tool set and running these checks from Amazon Web Services (AWS). AWS has some tooling to perform a type of synthetics check from CloudWatch, called Canaries, though in practice either route to synthetics checks on AWS involve a good amount of DIY work, and as you’ll see in this article, the real costs involved are similar.
The real costs of AWS Synthetics are Operational
When we consider the costs of AWS, the real differentiator between the public cloud and a dedicated service like Checkly is the Operational cost. For the moment we won’t discuss Infrastructure costs on AWS deeply, except to note that the cost of a DIY solution made with the most readily available tools does have a considerable costs. As a single example, you’ll quickly find that to run synthetic user tests effectively, you’ll want to send requests from static IP addresses. This will add to the bare-bones pricing of a simple container or AWS Lambda
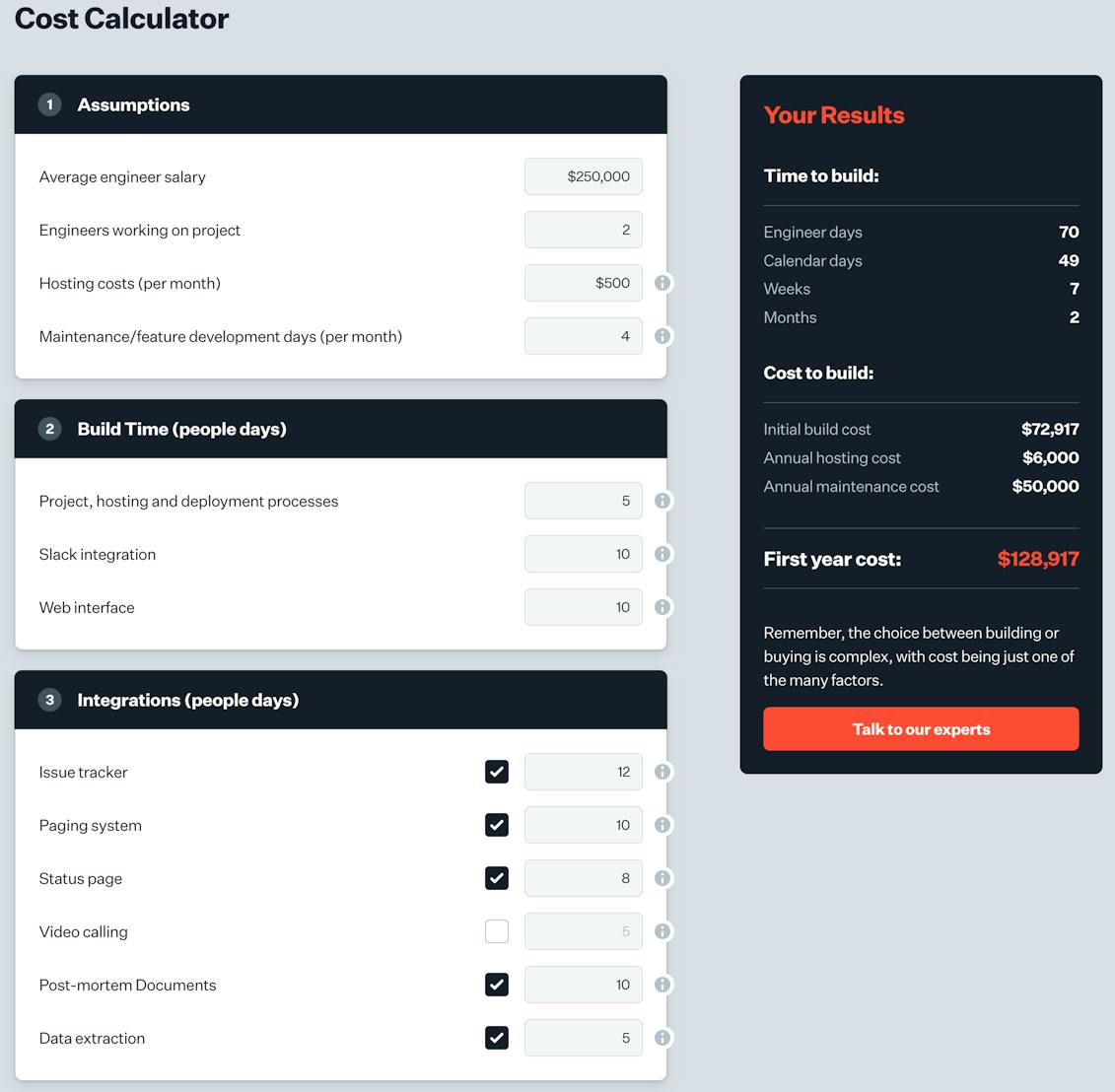
To start this discussion, check out the build vs. buy calculator from the incident.io team. I’ll use this calculator for a quick back-of-the-envelope figure for the first year cost of an AWS Synthetics solution.
Estimating the cost of AWS Synthetics
I want to make generous assumptions about the initial build time and maintenance of an AWS-hosted Synthetics tool. First off let’s assume our DevOps, SRE, or testing specialists are familiar with the language they’ll be using to write tests. It seems like a number of users of CloudWatch canaries are hitting that roadblock, but I don’t want to take an extreme case. This gets us an initial development time of just a few weeks, and only a few days a month of maintenance work.
The low number of maintenance days per month may well be an issue. In the example of working with CloudWatch canaries, the test code must either be part of a CloudFormation template or stored as a code file in a bucket somewhere. That means its very unlikely that every engineer can easily be empowered to write and deploy their own synthetics test. That means our monthly maintenance budget is the only time that tests will be added or modified. More on some other drawbacks to this limitation in the next section.
Finally, no solution is going to include a UI out of the box. To make an interface as nice as Checkly’s, we’re really talking about a large engineering project. However for this example we’ll only require an integration with a paging system, Slack, and an issue tracker. With these, our estimation is for a “Quick and dirty” solution that will tell you what tests are failing where, but not a nice plot of the failure timeline. We also may well end up digging through logs for details on the failure.
Plugging these values into the Build vs. Buy calculator (and assuming that our estimates need no margin for error) we come up with a two month launch timeline and a first year cost of $120k
Again this system has the following limitations:
- Only a basic web interface
- Doesn’t let every developer add or modify tests
- Doesn’t have sophisticated sharing and access control
Let’s not even mention the things like Checkly’s visual testing recording that show the exact way the page broke as a small video. Those reach features will never be worked on if there are only a few days a month to even update tests!
Operational costs are about more than engineer pay
Beyond the direct expense of work on a testing and monitoring system, it really stands to consider the cost of tests that are not of the highest quality. When we use either CloudWatch canaries or from-scratch DIY tests, we’re using a system with its own rules that will be fairly opaque to most of the developers on your team.
When using a SaaS option like checkly, you’re empowering each developer to write tests in javascript, and even to commit their tests write next to their code repository with Monitoring as Code. This has a number of advantages:
- When the developer who worked on a feature writes the test, they’re not working on a black box. They’re testing the most important part of the system since they know its internals.
- Testing should take lest time to write
- When looking at early feedback from synthetics tests, the developers can modify tests as needed without working through a DevOps or SRE specialist to modify the tests
- When tests fail, either right away or months later, the developer being woken up to work on an incident will be the same one who wrote the feature and built the test. As developers we’re never going to remember everything about a feature we worked on weeks ago, but it will still help our response time!
(quick sidebar does anyone else feel weird using unordered lists in your writing now because ChatGPT always uses them? I wrote every word of this article. Here’s a sentence only a real human could write: purple monkey dishwasher)
And now for the REAL-real costs: the costs of downtime
What’s downtime worth? Recent research points says that “Every minute of downtime is thousands to millions of dollars in revenue losses and costly damage to brand reputation.”
Will using a DIY heartbeat monitor on AWS take your site down? Absolutely not. Will make downtime worse? Absolutely.
The first step to fixing a systemic failure is recognizing its existence, and if you’re running your own system with fractional engineering resources, there’s a good chance that when you hit real outages your system won’t warn you before your users do.
“That failure took the site down, unfortunately it also broke statusPageUpdaterService”
One of the great dangers of any DIY solution for uptime monitoring is a shared failure: the same service that should warn us of downtime fails when the site does, so we slumber on blissfully unaware until our outage is a hashtag on the website formerly known as Twitter. Not even the mighty AWS is immune to this effect. In 2020 a detailed postmortem mentioned that the status pages continued to show green for sometime since the Service Health Dashboard was normally updated with Cognito, which was down.
Shared failures are something that you can control for with AWS, with its regions and availability zones, and hosting your synthetics checks on a public cloud means you can completely isolate that service from the rest of your production environment. You can. You can. But will you? Will you actually take the time to stand up a health check monitor, a data store for those health checks, a dashboard, a notification service, and a pager integration service, all completely separate from your actual production service? If you do, bravo! But interdependency is always a risk, and a completely separate system adds significant development time.
Shared expertise improves response time
It’s important not to forget how knowledge sharing and decentralization benefit the overall technical response of a team. I discussed above the shared failure of a service and its status page at AWS. From that same postmortem, one detail from the same paragraph is worth highlighting:
We have a back-up means of updating the Service Health Dashboard that has minimal service dependencies. While this worked as expected, we encountered several delays during the earlier part of the event in posting to the Service Health Dashboard with this tool, as it is a more manual and less familiar tool for our support operators.
When we DIY a solution, we are often siloing knowledge of that tool within our team: without a tool that can readily be used by every engineer, a DIY tool is often useful only to a few DevOps people. The result is a dashboard that, while functional, only makes sense to a few people. This is a problem if you’re not sure who will be directed to this dashboard during an outage.
While any tool, Checkly included, can be the victim of siloing, with its easy dashboards and ability to create accounts for anyone on your team who needs access, Checkly makes it a lot easier to share monitoring data from your entire organization
Conclusions: Operational Costs Matter
All of us who work in Operations know that infrastructure and service costs are only a small part of the story. Without considering the costs of setting up and maintaining services, we can easily get deluded by the sticker price, and end up with a massive workload for SREs and Operations engineers who are overworked as it is.
The allure of a "do-it-yourself" approach with AWS might seem appealing at first glance, due to perceived flexibility and control. However, when we account for the significant operational overhead—development time, maintenance, and the expertise required to manage and update tests—the cost advantage begins to diminish.
The comparison laid out in this post underscores a fundamental truth in software development and operations: efficiency and reliability often come at a cost that's not immediately apparent. While AWS provides powerful tools for building custom synthetic testing solutions, the investment in time and resources can quickly outpace the initial estimates. This is especially true when considering the need for a robust, user-friendly interface and the ability to empower every developer to write and modify tests without bottlenecking through a few specialized engineers.
Checkly's lets engineers throughout your organization write tests and run them with zero friction, significantly reduces the operational burden on teams. It enables developers to focus on what they do best—building and deploying great software—rather than getting bogged down in the intricacies of maintaining a custom testing framework.