

Today’s a big day at Checkly; we’re thrilled to announce that next to Browser and API checks we released a brand new check type to monitor your apps — say “Hello” to Heartbeat checks!
In the realm of software, ensuring uninterrupted functionality is critical. While synthetic monitoring helps you discover user-facing problems early, keeping a close eye on the signals coming from your backend can be just as vital.
Whether you’re building a hobby project on a single server or are part of a team managing an enterprise solution of micro-services, understanding and using heartbeat monitoring is a key tool to increase the reliability of your product. But what is heartbeat monitoring?
The Basics of Software Heartbeats
Heartbeat monitoring refers to the checking of periodic signals a system sends out to indicate its operational status. Think of it as software saying, "I'm still here and working as expected." When even a minute's downtime can translate to significant revenue loss, reputation damage, or worse, missing a beat is not an option.
A heartbeat typically manifests as a recurring message or signal, such as an HTTP request, generated by a service, system, or application. This signal, sent at regular intervals, is monitored by either a parent system or an external monitor. If the signal is missed or shows anomalies, it acts as a red flag indicating potential issues.
Heartbeat monitoring is also known as CRON monitoring since it is often used to monitor CRON jobs or similar scheduled tasks. It can also be referred to as a ‘dead man’s switch’ from the type of fail-safes found on heavy machinery or vehicles that function similarly in the physical world.
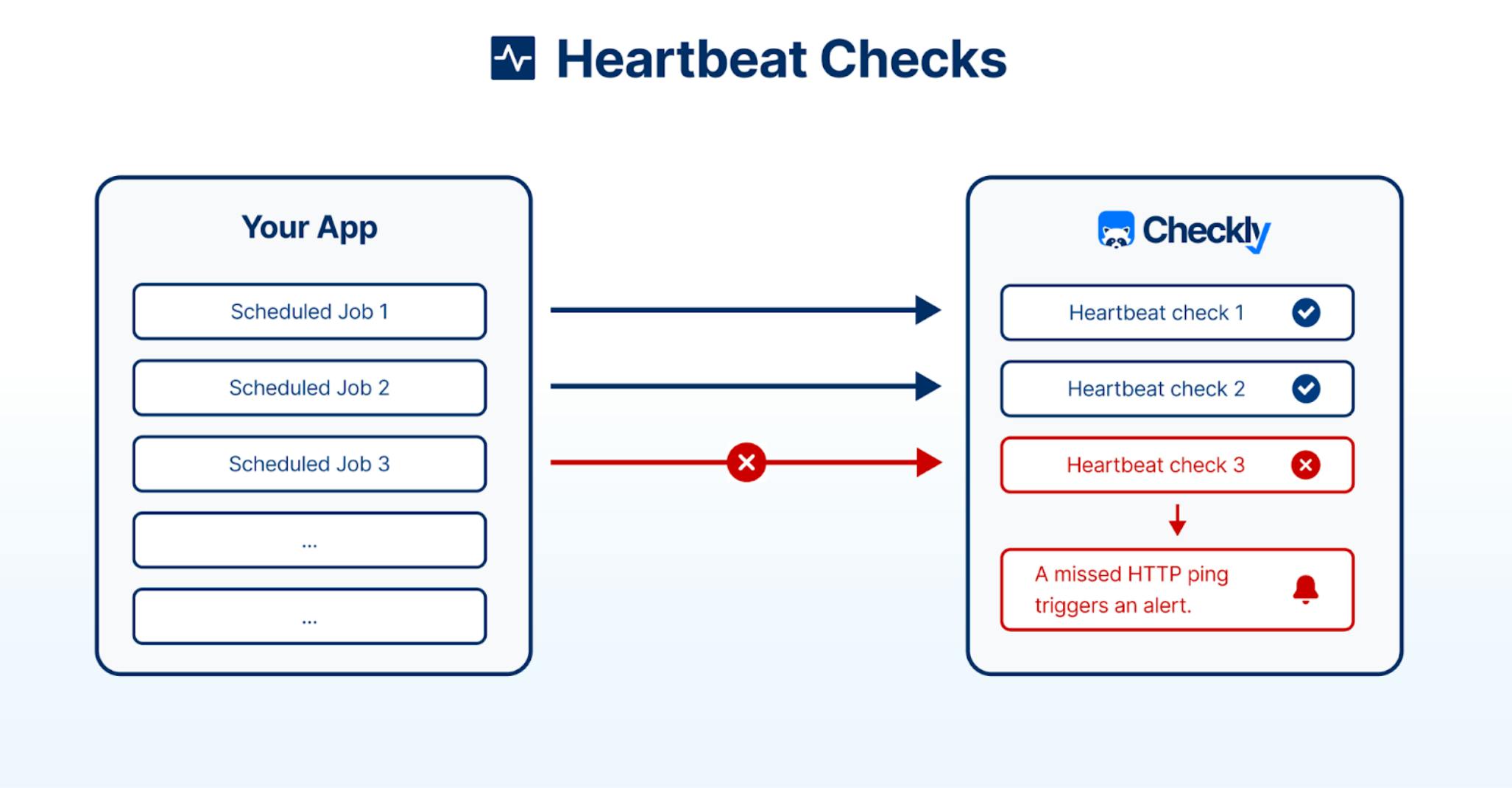
In the diagram above, we can see how this is implemented using Checkly’s Heartbeat checks. The backend of the monitored service runs a number of automated jobs; these can be backup jobs, database updates, or schedulers sending emails. If these succeed, they ping the Checkly cloud to signal their heartbeat with an HTTP ping to a unique Checkly URL.
Checkly will monitor and listen for the defined heartbeats. If a heartbeat check does not receive a ping within the expected timeframe; it will trigger an alert, which reaches out via the configured channels to the responsible team or on-call engineer.
Why Use Heartbeat Monitoring?
The expectation for software systems and services is clear: they must be available, responsive, and reliable. That is why heartbeat monitoring is non-negotiable.
“Few things in site reliability are as frustrating as having a system go down only to learn that your backup scripts stopped running at some point and you didn't notice. Checkly's heartbeat feature made it extremely simple to monitor my backup process for reliable execution.”
- Dan Subak, Software Engineer, Memfault
Ensuring Service Uptime and Availability
Consumers and businesses rely heavily on digital services. Any downtime can lead to lost revenue, tarnished reputations, and diminished trust. Heartbeat monitoring acts as an early warning system for your backend, ensuring potential issues are identified and addressed before they escalate or become an end-user problem.
If the job to update all user tables with the latest information fails, you want to know it before users report that their data is stale. With heartbeat monitoring, you can get notified as soon as the first job is late.
Early Detection of System Failures or Malfunctions
Not all system issues immediately result in complete outages. Some might degrade the system's performance over time or elevate what would otherwise have been a minor incident.
A backup job that is not running might not directly cause problems for your users, but restoring a faulty database becomes a nightmare when the job has failed silently for a month. Regular heartbeat checks flag these anomalies early, allowing teams to troubleshoot and rectify them proactively.
Using Checkly to Implement Heartbeat Monitoring
Now that we have a clear understanding of what heartbeat monitoring and its applications are, it's time to implement it into your infrastructure.
If you are a Checkly user, setting up reliable heartbeat checks can be done in two steps.
Create a Checkly heartbeat check
To create a heartbeat check, click the + sign in the sidebar and choose ‘Heartbeat’. From here, you need to give your check a name and select the period and grace for the check.
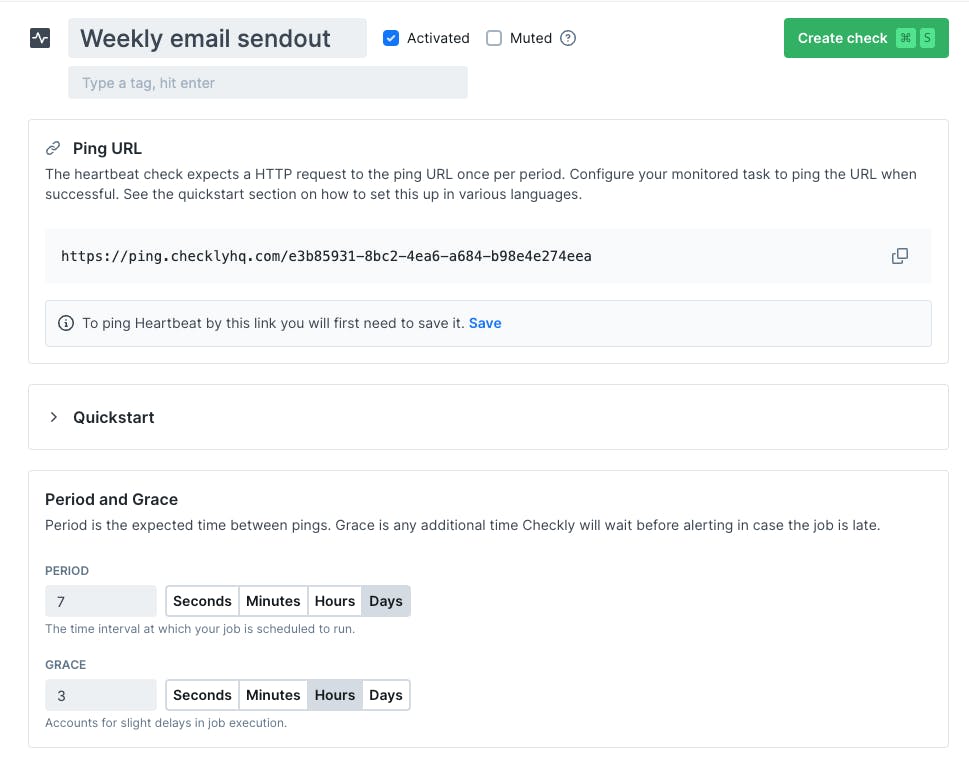
The Heartbeat period defines how often the check expects a ping and should correspond with however often the job or task you are monitoring runs.
The Heartbeat grace gives some leeway before the check considers the ping late and is used to account for variance in the execution time. Sometimes a job takes 30 seconds to finish, other times two minutes. Grace is used to reduce the risk of incorrect alerts because of this variation. We recommend always using at least 30 seconds of grace to accommodate unexpected slowdowns and lower the risk of false positives.
You can also use the Checkly CLI and Monitoring as Code (MaC) to create and update your heartbeat checks directly from your IDE of choice. The MaC approach allows you to track your Checkly monitoring setup in version control and share your configuration across workflows and projects.
import { HeartbeatCheck } from 'checkly/constructs'
new HeartbeatCheck('heartbeat-run-backups', {
name: 'Run backups',
activated: true,
muted: false,
period: 6,
periodUnit: 'hours',
grace: 10,
graceUnit: 'minutes',
alertChannels: [smsChannel, emailChannel],
tags: [],
})
If you are unfamiliar with the Checkly CLI and Monitoring as Code, see what Tim, our CTO, says about it here: Monitoring as Code in your Software Development Lifecycle.
Checkly also offers the code exporter, letting you get started in the UI and later export your checks to the CLI or to Terraform.
After you created a Heartbeat check it’s time to activate it. Onwards!
Add the ping URL event to your job, service or server
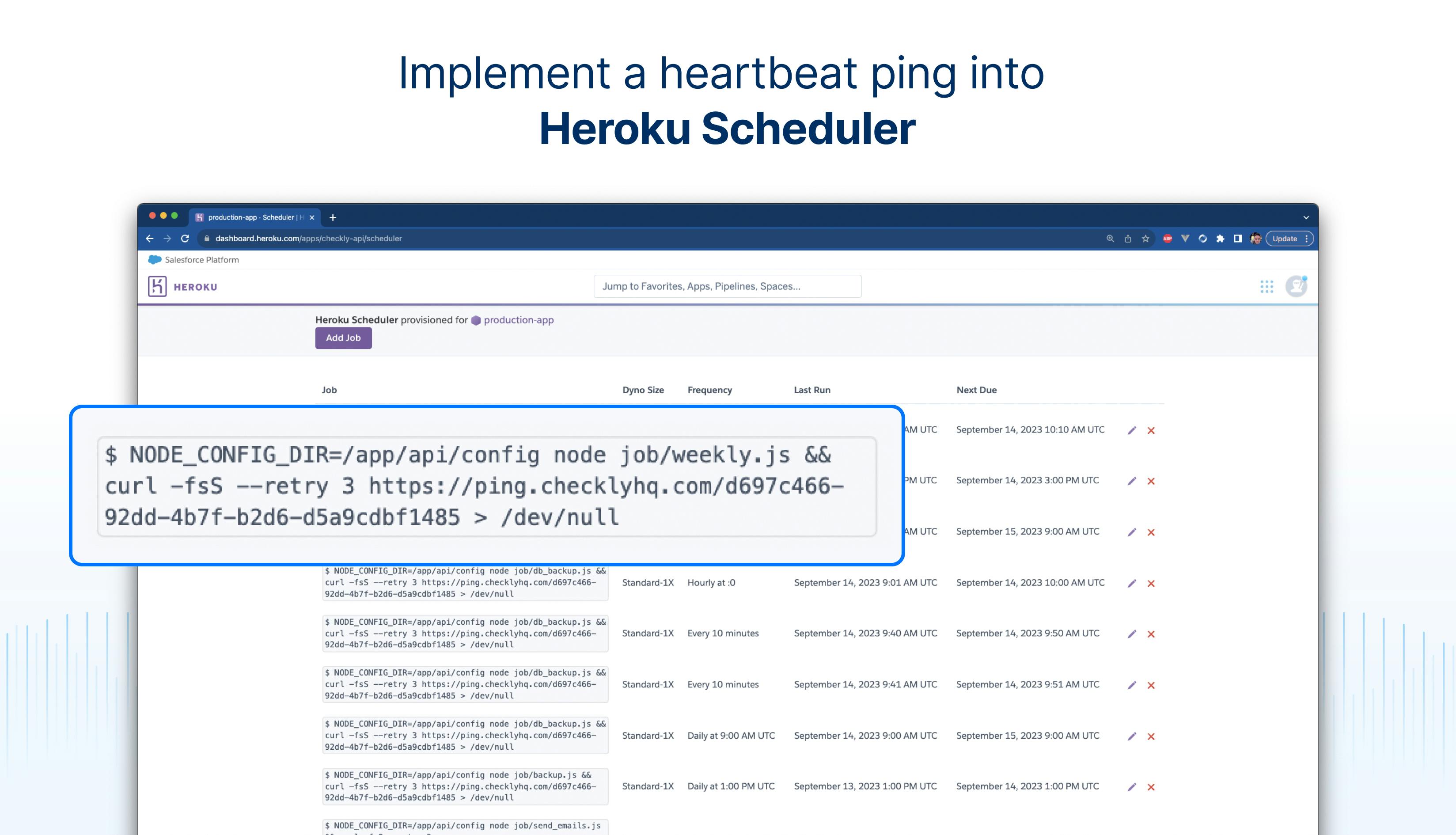
Since heartbeat checks rely on pings from the service being monitored we need to add the ping event to the job. How to do this varies depending on the language the job is written in, and we provide various examples in our documentation. One of the more common use cases is to monitor cron jobs written using Bash:
# run_backup.sh
PING_URL=https://api.checklyhq.com/heartbeats/ping/4e4e488a-76bc
curl -m 5 --retry 3 $PING_URL;This simple way of creating a ping makes it very easy to monitor jobs running on e.g Heroku or GitHub actions.
For more details on using heartbeat checks, have a look at the Checkly documentation.
Reacting to and analyzing failed heartbeats
A heartbeat check that doesn’t receive the expected ping within the specified time will trigger an alert. You can configure your alerting settings so alerts are sent only after a check has failed more than once to avoid disturbing your engineering team in non-critical situations. Heartbeat check alerts can reach your team via all of Checkly's available alerting channels, ranging from email to phone calls, depending on the level of urgency.
Note that, unlike API or browser checks, a failing heartbeat check will not provide a lot of information in the ping result, as it requires the failing service itself to send the ping with information. Instead, the recommended route for troubleshooting a failing heartbeat is to go directly to the service or job that did not report on time and look for any logs or reports from the job to understand the root cause for the missing or late ping.
Because of this, it is important to name your heartbeat check in a way that allows a responding engineer to quickly identify which job failed, reducing the time to resolution. You can also provide a source in your successful pings. This additional meta information can let your team quickly identify which server or service a heartbeat check is monitoring by looking at the result of a successful ping.

Conclusion
The need for reliability to establish user trust makes heartbeat monitoring indispensable for any modern software organization. Lower the risk of undetected issues causing large-scale damage over time and reduce developer time needed to identify and address backend problems.
Let us know what you think, and set up your heartbeat checks with the Checkly CLI today. The setup and management of heartbeat checks is both low-effort and easy to scale. And if you have feedback, we’re always happy to hear it in the Checkly community Slack.
Until then, never miss a heartbeat!




