Making the switch from Datadog to Checkly
A quick guide to help you evaluate Checkly as a focused alternative to Datadog's synthetic monitoring.
What is Datadog?
Datadog is a comprehensive observability platform that combines metrics, logs, traces, and synthetic monitoring into a single product. While powerful, its breadth comes at the cost of complexity and rapidly escalating bills.
What is Checkly?
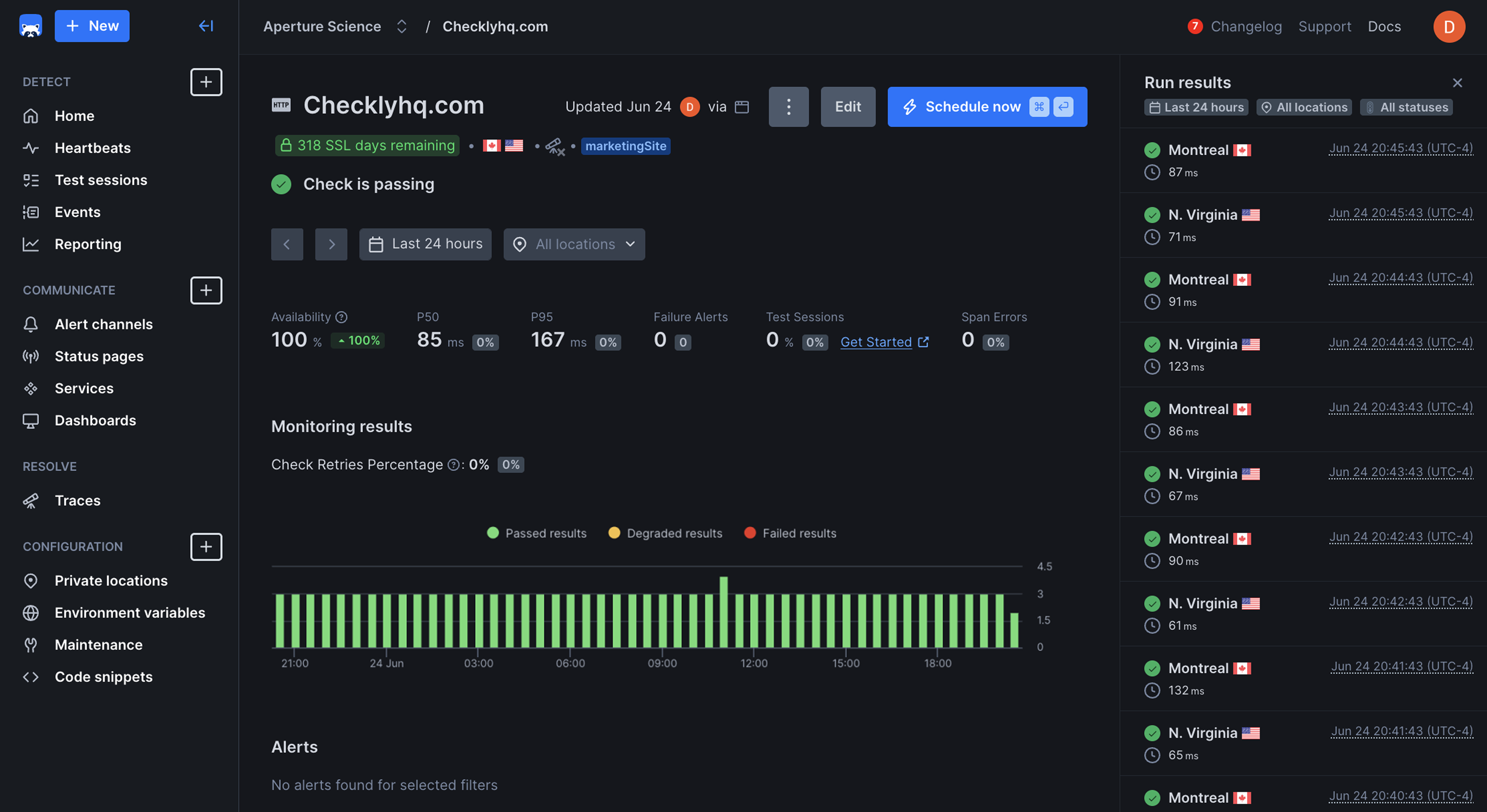
Checkly helps thousands of software teams improve their application reliability with a platform built for engineers to take control of their testing, monitoring, and incident management.
Create and reuse tests using Playwright or OpenAPI, run them locally or in CI/CD, then deploy them to our global infrastructure to monitor your applications and services at high-frequency 24/7.
If anything fails or degrades, you and your teams will be alerted instantly and your status page updated.
Why teams switch to Checkly
Datadog often presents three critical challenges that hold engineering teams back:
1. Overwhelming complexity and cognitive load
Datadog tries to do everything—APM, logs, metrics, synthetic monitoring, security, and more. This creates a cluttered interface where finding what you need requires extensive training. Teams spend more time navigating dashboards than solving problems.
2. Unpredictable and escalating costs
Datadog's pricing model is notoriously complex with charges across multiple dimensions—hosts, containers, custom metrics, log ingestion, and more. Bills can spike unexpectedly as your usage grows, making budgeting difficult. Many teams discover their monitoring costs rival their infrastructure costs.
3. Synthetic monitoring as an afterthought
While Datadog offers synthetic monitoring, it's clearly not their focus. Browser test capabilities lag behind dedicated solutions, configuration is cumbersome, and the feature set feels bolted-on rather than thoughtfully integrated. Teams wanting robust end-to-end testing often need supplementary tools.
Benefits of Checkly
How Checkly Improves Reliability
1. Built for how modern product & platform teams actually ship
Most monitoring tools grew up around infrastructure dashboards or generic uptime checks. Checkly is built around applications and user journeys first.
- •Model reliability as checks (browser, API, cron, TCP) that mirror real behaviour.
- •Validate flows like sign-up, checkout, SSO, or critical APIs from multiple regions.
- •Treat your monitoring setup as a first-class part of the application, not an afterthought.
Result: You get coverage that matches how users actually experience your app — not just whether an endpoint returns 200.
2. Optimized for developer experience and Monitoring as Code
Checkly leans into the workflows developers already use: JS/TS, Playwright, CI/CD, Git.
- •Checkly CLI: define checks, alert policies, and environments as code.
- •Playwright Check Suites: reuse your existing Playwright tests as production monitors.
- •Terraform & Pulumi providers: manage monitors like you manage infra.
Monitoring as Code means you:
- •Version control every monitor and alert.
- •Review changes with pull requests.
- •Roll forward and back safely.
- •Scale your monitoring footprint programmatically as you add services.
3. Scales with your systems and your org
As companies grow, DIY scripts and UI-driven configs start to fall over. Checkly is built to scale from a single product team to large, multi-service organizations:
- •Global public locations + private locations for internal services.
- •Environments, projects, and code-based configuration for multi-team setups.
- •Enterprise plans with SLAs, SSO/SAML, long retention, and dedicated support when you're ready.
Result: You can keep your monitoring model clean and maintainable even as you add more services, regions, and teams.
4. One workflow to Detect, Communicate, and Resolve
Checkly stitches together what most stacks treat as separate tools:
- •Detect issues proactively with high-frequency uptime checks and Playwright-based synthetics.
- •Communicate clearly with status pages and rich, routed alerts (Slack, SMS, webhooks, Opsgenie, etc.).
- •Resolve faster using Checkly Traces and deep error context so engineers know exactly what went wrong.
Instead of jumping between 3–5 tools, teams stay in one monitoring workflow from detection through to resolution.
How to make the move
The migration process
Here's a proven five-step process for successfully migrating to Checkly:
Create your Checkly account
Start with the free tier or a trial on a paid plan. Optionally install the Checkly CLI in a demo project to see Monitoring as Code in action.
Instrument your “golden paths”
Add a handful of critical uptime checks (core URLs, login, APIs). Build 2–5 Playwright checks for your most important browser flows (signup, checkout, SSO, key dashboards).
Run a pilot alongside your current tool
Run Checkly in parallel for 4–6 weeks. Compare signal quality, time-to-detect, developer adoption, and cost.
Codify your monitoring model
Move monitors and alert policies into code (Checkly CLI, Terraform, or Pulumi). Standardize naming, labels, alert rules, and environments across teams.
Switch fully and decommission legacy monitors
Migrate remaining checks and status communication into Checkly. Turn off overlapping monitors in your previous tools to avoid double-paging and double-billing.
Pitching Checkly
Need to pitch Checkly to your bosses?
Here are the key points to help you get stakeholder buy-in:
"We're going to save a boatload of money"
Teams typically save 30-50% on monitoring costs with Checkly's transparent, usage-based pricing.
"We'll catch and fix issues faster than our customers can report them"
Catch issues 2x faster with intelligent alerting and detailed error diagnostics. Multi-step checks catch complex failures that simple uptime monitors miss.
"We can actually monitor the things that earn us money"
Built on modern technologies and designed for modern workflows. Regular updates, active development, and a roadmap aligned with how teams actually work.
"Our developers can share and reuse tests and monitors"
Monitoring as Code means developers spend less time clicking through UIs and more time writing code. Deploy monitors as part of your release process, not as an afterthought.
Need an answer?
Frequently asked questions
Checkly offers flexible, transparent pricing with self-serve plans for smaller teams and custom enterprise contracts for larger organizations. Plans scale by uptime monitors and synthetic check volume, with discounts for annual commitments.
Yes. Checkly provides enterprise features like SSO/SAML, SOC certifications, and is available via the AWS Marketplace with defined SLAs and long data retention on higher tiers.
Yes. Checkly's Private Locations let you run checks against internal services and non-public endpoints from within your own infrastructure.
Checkly integrates with CI/CD, Slack, incident management tools, and IaC tools like Terraform and Pulumi. You can trigger checks in pipelines, route alerts into existing channels, and manage monitors alongside your infrastructure code.
Most teams start by running Checkly in parallel for critical flows. You can prove value and build momentum internally while your existing contract runs down, then switch fully once you're ready. (If you're going through AWS Marketplace, you can often align Checkly contracts with broader AWS commitments.)
Helpful resources
Ready to make the switch?
Our team will guide you through every step of the migration process.