Sometimes the internet is flaky, or your app is just having a hiccup not worth pinging your on-call team about. Retries are your first line of defense against these types of false positives, leading to alert fatigue.
Whether you need to retry a check or a test session, there are different retries available.
Use Retries instead of the deprecated “double check” option.
Check retry strategies
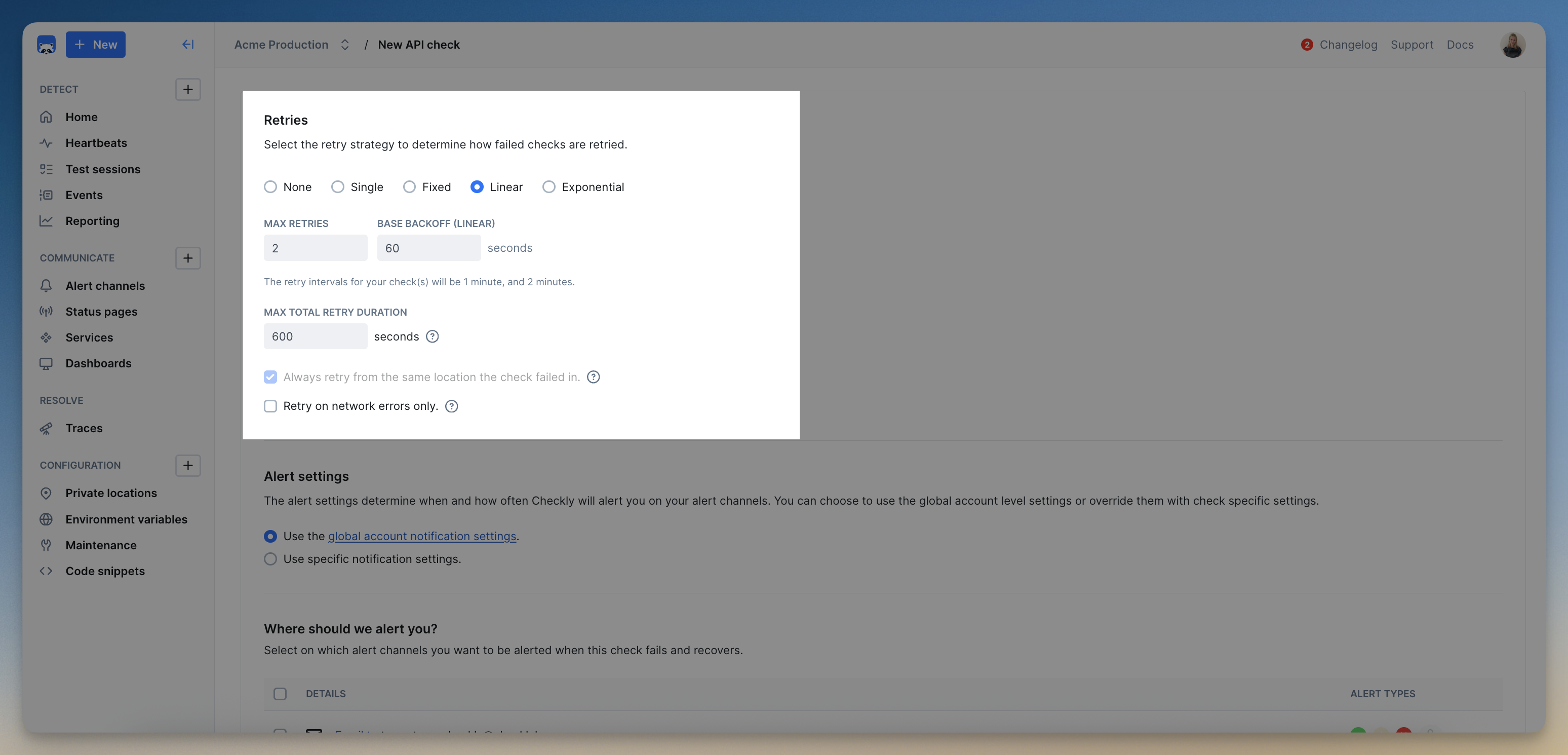
All check types and check groups, except for Heartbeat monitors, have a Retries & Alerting section available, where you can define the number of retries and which retry strategy your check or check group uses.
Click Edit check or Edit group on the 3-dot menu on your Checkly Home page and select the Retries & Alerting tab:
Scheduled check retries
There are three distinct retry strategies based on the time between retry attempts, and each one comes with different retry/backoff characteristics.
- Single — retry once after a fixed interval, e.g. 5s.
- Fixed — a fixed time between retries, e.g. 5s, 5s, 5s etc.
- Linear — a linearly increasing time between retries, e.g. 5s, 10s, 15s etc.
- Exponential — an exponentially increasing time between retries, e.g. 5s, 25s, 125s (2m and 5s) etc.
On top of the time between attempts, you can also set:
- maximum number of retries - the maximum number of retries for this check or check group.
- maximum total retry duration - the maximum time a check can be in a retrying state.
This is a timeout to ensure the check finishes on a timely manner.
Make sure to include the time your check needs to run when setting the maximum total retry duration. For example, if you set a maximum to 2 minutes, and your check takes 1.5 minutes, you have 30 seconds left for retries.
How often should I retry?
For checks that run on lower frequencies, e.g. once per hour, it makes sense to pick a strategy that retries more often, over longer stretches of time. Let’s look at an example:
- A check with a 1-hour frequency breaks at 13:00 CET.
- An exponential retry strategy with 3 retries and a 5-second interval is configured.
- This generates retries spaced apart by 5 seconds, 25 seconds, 125 seconds.
- Your check is now retried at about 13:00:05, 13:00:30 and 13:02:35.
If in that ~3-minute period your app / system recovers, and this was just a fluke, you will not be alerted. If the issue persists, Checkly will alert you as per your alert settings.
For checks that run on higher frequencies, e.g. once per minute, it makes sense to pick a strategy that retries less often, and spaced apart by shorter intervals.
Of course, picking the right strategy depends on your use case, tolerance for intermittent failures, SLO levels and other factors.
Location-based check retries
You can decide if a check should be retried from the same location or not with the checkbox:
Always retry from the same location the check failed in
- If enabled, a check that fails will be retried in the same location.
- If disabled, a check that fails will be retried in a different location, from the locations your check runs at.
There are some tradeoffs to consider:
- Retrying from the same location makes sense if you care strongly about the uptime of your app in one specific location, compared to other locations.
- Retrying from a different location makes sense, if you want to make sure your app is up in at least one location.
Network retries
For API checks & URL monitors, you can enable network retries to automatically retry a check run only if it fails due to a network error—such as a timeout, DNS resolution issue, or connection reset.
When network retries are enabled:
- The check will retry on: ECONNRESET, ENOTFOUND, ETIMEDOUT, EAI_AGAIN, ECONNREFUSED, and similar network errors.
- The check will not retry on: Any HTTP response that includes a status code (4xx or 5xx), failed assertions, or any other type of check failure.
Test sessions retries
Sporadically failing tests may be caused by a variety of reasons such as issues with the underlying infrastructure, and sometimes, simply re-running the test is enough to make it succeed again.
Use retries to reduce noise in your test session results while providing information about the retry attempts.
Specify the number of retries between 0 and 3 that you’d like Checkly to attempt when running npx checkly test or npx checkly trigger.
The default number of retries is 0.
You can configure the number of test session retries as a global setting in your Checkly configuration file:
Using the CLI and the --retries= flag takes precedence over your Checkly configuration file.
All retry attempts are be visible on the web interface at Checkly and in your command line as they’re happening:
Test session retries in your CI/CD pipeline
Use the --reporter=ci flag to run test session retries from your CI/CD pipeline. The ci reporter will print out all retry attempts in the prompt output, instead of live-updating the prompt.
For example: