This page describes a new V2 version of the Prometheus exporter. For information about the old Prometheus exporter, see the Prometheus V1 docs.
Activation
Activating this integration is simple.-
Navigate to the integrations tab on the account screen and click the ‘Create Prometheus endpoint’ button.

-
We directly create an endpoint for you and provide its URL and the required Bearer token.
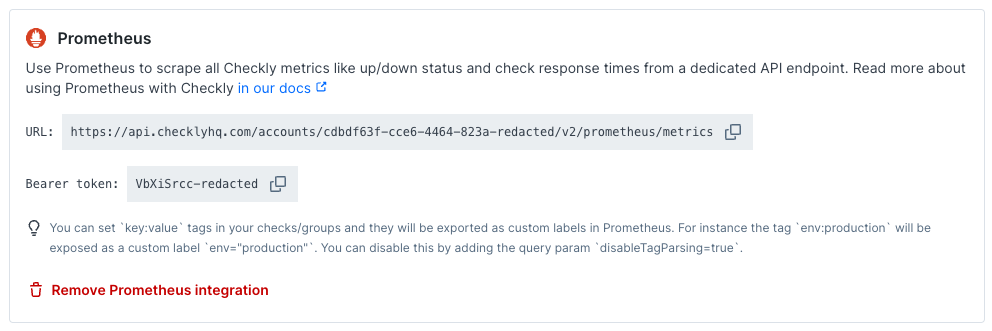
-
Create a new job in your Prometheus
prometheus.ymlconfig and set up a scraping interval. Use a 60-second scrape interval and enable compression. Add the URL (divided intometrics_path,schemeandtarget) andbearer_token. Here is an example
The Prometheus metrics endpoint has a rate limit of 50 requests per minute.
The responses from this endpoint are cached for 60 seconds.
Any request made to this endpoint within 60 seconds of the initial request will receive the cached response.
Use a scrape interval of 60 seconds. Shorter intervals fetch the same cached data.
If you run multiple Prometheus instances, each instance scrapes independently. Align their scrape intervals where possible.
Check Metrics
The Prometheus exporter exposes several metrics you can use to monitor the status of your checks, as well as to inspect detailed information such as Web Vitals. The following metrics are available to monitor checks:
The
checkly_check_status and checkly_check_result_total metrics contain a status label with values passing, failing, and degraded.
The checkly_check_status gauge is 1 when the check has the status indicated by the status label and is 0 otherwise.
For example, if a check is passing the result will be:
checkly_check_status can be useful for viewing the current status of a check, whereas checkly_check_result_total can be useful for calculating overall statistics.
The metrics checkly_browser_check_web_vitals_seconds, checkly_browser_check_errors, checkly_api_check_timing_seconds, checkly_tcp_monitor_timing_seconds, checkly_icmp_monitor_timing_seconds, and checkly_dns_monitor_timing_seconds contain a type label.
This label indicates the different Web Vitals, error types, and timing phases being measured.
For checkly_tcp_monitor_timing_seconds, the type label has the following values: dns, connection, data, and total.
For checkly_icmp_monitor_timing_seconds, the type label has the following values: dns (DNS resolution time), latency_avg, latency_min, and latency_max.
For checkly_dns_monitor_timing_seconds, the type label has the value total.
checkly_time_to_ssl_expiry_seconds contains a domain label giving the domain of the monitored SSL certificate.
In addition, the check metrics all contain the following labels:
You can setkey:valuetags in your checks and groups and they will be exported as custom labels in Prometheus. For instance the tagenv:productionwill be exposed as a custom labelenv="production". You can disable this by adding the query paramdisableTagParsing=true. Please note that Prometheus label names may only contain ASCII letters, numbers, as well as underscores (see the official docs). Tags containing other characters in the label name will be sanitized.
The counter and histogram metrics are reset every hour. These resets can be handled in Prometheus by using the rate or increase functions.
Check Run Location Label
To avoid creating a high volume of metrics, by default the metrics don’t include a label for the check run location. It is possible to enable this by adding the query paramlocationLabelEnabled=true to your API request. This will add a location label giving the location where the checks ran.
Since check status and SSL days remaining is only tracked on a per-check basis rather than by location, checkly_check_status and checkly_time_to_ssl_expiry_seconds do not have the location label included. Heartbeat metrics (checkly_heartbeat_last_success_timestamp_seconds, checkly_heartbeat_expected_interval_seconds, and heartbeat entries in checkly_check_result_total) also do not have a location label, since heartbeat monitors receive pings rather than running from specific locations. All other check metrics will have the location label added.
Here is an example for how to set this in your prometheus.yml config:
Check Retry Attempts
By default, retry attempts are not included in the reported metrics. For example, if a check is failing on the initial attempt and passing on the retry,checkly_check_result_total and other metrics will only report the final passing check result.
It is possible to include retry attempts by adding the query param includeRetryAttempts=true to your API request. Metrics reporting information on check results will then include retry attempts.
An exception to this behaviour is checkly_check_status, which reports whether the check is currently in a passing, degraded, or failing state. Since retry attempts don’t affect the checks state and only the final check result determines the state, this metric ignores retry attempts regardless of the includeRetryAttempts setting. For example, if a check is failing on retry attempts and passing on the retry, checkly_check_status will report that the check is passing.
Here is an example for how to configure includeRetryAttempts in your prometheus.yml config:
PromQL Examples
This section contains a few PromQL queries that you can use to start working with the Prometheus data.Currently failing checks
To graph whether checks are passing or failing, use the query:1 while failing and degraded checks will have the value 0.
This can be used to build a Grafana table of currently failing checks.
Failure percentage
To calculate the percentage of check runs that failed in the last 24 hours, use:Histogram averages
The different histogram metrics can all be used to compute averages. For example, query the average web vitals times for a check using:Heartbeat Metrics
Heartbeat monitors are passive checks that wait for your scheduled jobs and automated processes to send a ping. The Prometheus exporter includes heartbeat checks in the standardcheckly_check_status and checkly_check_result_total metrics, plus two heartbeat-specific gauges designed for dead man’s switch alerting.
checkly_heartbeat_last_success_timestamp_seconds— The Unix timestamp of the last successful ping, searched across the entire event history (no time window). A value of0means no successful ping has ever been received — this immediately triggers a dead man’s switch alert sincetime() - 0produces a very large value.checkly_heartbeat_expected_interval_seconds— The maximum expected time between pings, derived from the heartbeat monitor’s configured period and period unit (e.g.,5 minutes=300seconds). Use this as a threshold for alerting.
How heartbeats map to checkly_check_result_total
Heartbeat checks contribute to checkly_check_result_total using a 1-hour count window, the same as other check types. The status label values map to heartbeat event states as follows:
Dead Man’s Switch PromQL Examples
Alert when a heartbeat ping is overdue
Compare the current time against the last success timestamp. If the difference exceeds the expected interval, the job has missed its window:Alert with a safety margin
Add a grace period multiplier (e.g., 1.5x) to avoid false alarms from minor delays:Grafana table of heartbeat health
Show how long ago each heartbeat was last seen:Private Location Metrics
The Prometheus exporter also contains metrics for monitoring Private Locations. These metrics can be used to ensure that your Private Locations have enough Checkly Agent instances running to execute all of your checks, and to drive agent autoscaling. The following metrics are available to monitor Private Locations:
The Private Location metrics all contain the following labels:
checkly_private_location_check_runs additionally carries a state label. The values relevant for autoscaling are:
queued— the check run has been scheduled but not yet picked up by an agent.inflight— the check run is currently being executed by an agent.
checkly_private_location_queue_duration_ms additionally carries two labels:
stat— the statistical aggregation over the 2-minute window. Values:avg,p90,p99.queue— the internal routing queue the check run was scheduled to. Values:uptime,main.
This gauge is aggregated on a ~1 minute interval, so check runs that start and finish within that window may be excluded.